Compilazione e reverse engineering
In questo capitolo vengono trattati il tema del linguaggio macchina e il processo di compilazione. Vengono poi introdotte le principali tecniche per fare reverse engineering di file eseguibili, ovvero per provare a capirne il funzionamento e la logica interna senza avere a disposizione il codice sorgente da cui sono stati generati.
La CPU e il linguaggio macchina
La CPU (Central Processing Unit) è il componente principale di un computer, è responsabile dell'esecuzione delle istruzioni di ogni programma. La CPU elabora delle istruzioni elementari in un ciclo composto da tre fasi:
- fetch (prelievo), ovvero l'istruzione viene letta dalla memoria RAM
- decode (decodifica) ovvero i byte corrispondenti all'istruzione vengono decodificati e interpretati
- execute (esecuzione) ovvero l'istruzione viene eseguita.
Una istruzione potrebbe svolgere calcoli aritmetici, logici, controllo del flusso, scritture o letture in memoria RAM, oppure interazioni con l'hardware o il sistema operativo.
La CPU ha al suo interno dei registri, che mantengono, insieme alla memoria RAM, lo stato di esecuzione del programma. Tra questi, uno dei più importanti è il program counter (a volte denominato instruction pointer), che mantiene l'indirizzo della prossima istruzione da eseguire. Alcune istruzioni possono cambiare il valore di questo registro, ad esempio quando si vuole chiamare una funzione oppure saltare a specifiche istruzioni.
La CPU quindi, può interpretare solamente il proprio linguaggio macchina che è composto da una sequenza di byte. Possiamo interpretare questa sequenza per renderla leggibile tramite l'uso di un disassemblatore, che ci restituisce il codice assembly corrispondente. Queste due rappresentazioni contengono esattamente le stesse informazioni, e si può passare da una rappresentazione all'altra con facilità. Ad esempio la sequenza di byte
554889e54883ec10c745f402000000c745f8030000008b55f48b45f801d08945fc8b45fc89c6
corrisponde al seguente codice assembly
push rbp
mov rbp,rsp
sub rsp,0x10
mov DWORD PTR [rbp-0xc],0x2
mov DWORD PTR [rbp-0x8],0x3
mov edx,DWORD PTR [rbp-0xc]
mov eax,DWORD PTR [rbp-0x8]
add eax,edx
mov DWORD PTR [rbp-0x4],eax
mov eax,DWORD PTR [rbp-0x4]
mov esi,eax
In questo modulo ci concentreremo sul linguaggio macchina x86, che è attualmente il più diffuso tra i computer desktop e server. Non è però l'unico possibile, per esempio il set di istruzioni ARM è molto diffuso nell'ambito degli smartphone e ultimamente anche di alcuni portatili e server. Altre architetture sono possibili, per citarne alcune RISC-V, AVR, MIPS, e molte altre.
Si assume una familiarità di base con il linguaggio assembly e soprattutto con x86, è possibile comunque fare riferimento al manuale ufficiale Intel, e alle varie guide e libri disponibili online.
Il processo di compilazione
Un compilatore è un programma che traduce il codice sorgente scritto in un linguaggio di programmazione ad alto livello, come C++ o Java, in un linguaggio macchina comprensibile ed eseguibile dalla CPU. Il risultato finale è un file binario eseguibile, che può essere eseguito direttamente dalla CPU senza la necessità del codice sorgente originale.
Prendiamo per esempio un semplice programma scritto in C.
#include <stdio.h>
int main (){
puts("Hello World!");
return 0;
}
Possiamo compilarlo con un compilatore, e possiamo ispezionare il codice assembly generato tramite degli strumenti come objdump.
$ objdump -M intel -d main
[...]
0000000000001139 <main>:
1139: 55 push rbp
113a: 48 89 e5 mov rbp,rsp
113d: 48 8d 05 c0 0e 00 00 lea rax,[rip+0xec0] # 2004 <_IO_stdin_used+0x4>
1144: 48 89 c7 mov rdi,rax
1147: e8 e4 fe ff ff call 1030 <puts@plt>
114c: b8 00 00 00 00 mov eax,0x0
1151: 5d pop rbp
1152: c3 ret
Possiamo chiaramente identificare l'istruzione che chiama la funzione puts, ovvero
call 1030 <puts@plt>
e le istruzioni che fanno ritornare 0 dalla funzione (il valore di ritorno di una funzione in x86 è messo nel registro rax)
mov eax,0x0
pop rbp
ret
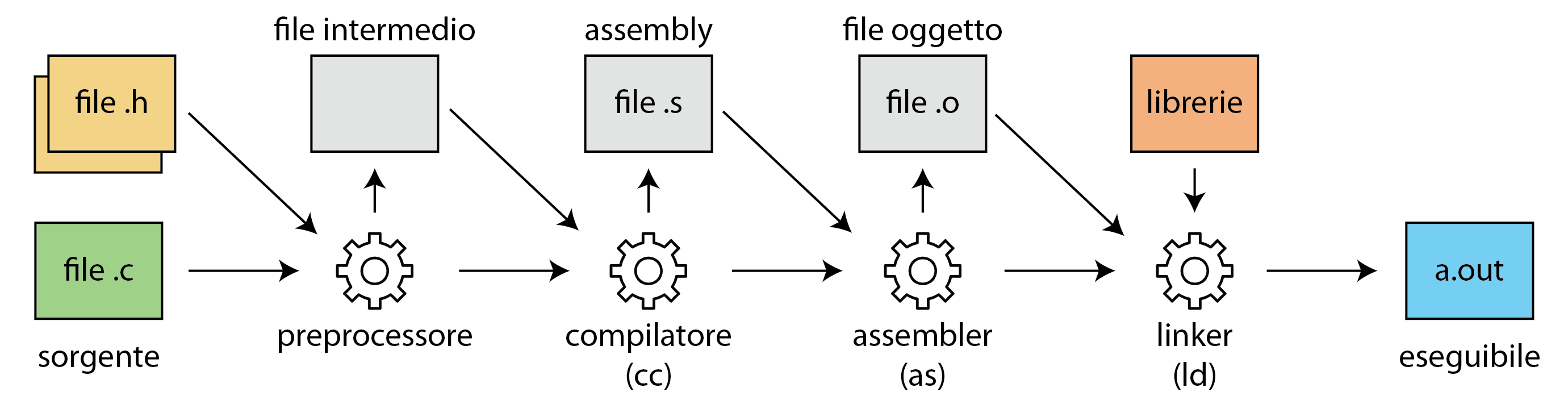
Il processo di traduzione che porta dal codice sorgente al programma eseguibile attraversa varie fasi di compilazione e ottimizzazione. Ad esempio un compilatore per il linguaggio C deve prima eseguire il preprocessore, che risolve tutte le direttive ottenendo il codice sorgente completo. Questo poi passa al compilatore vero e proprio, che trasforma un file sorgente (più nello specifico una translation unit) in codice assembly. Infine l'assemblatore trasforma il file assembly in un file oggetto.
Questo però non è ancora eseguibile, perché potrebbe avere delle dipendenze con librerie o con altri file oggetto. Queste dipendenze sono risolte dal linker, che combina tutti i file oggetto in un unico file eseguibile. Il processo di linking può essere statico, ovvero le librerie sono incorporate all'interno del binario finale, oppure dinamico, ovvero vengono lasciate delle reference alle librerie necessarie, che saranno poi caricate a tempo di esecuzione.
Principi di reverse engineering
Il reverse engineering è il processo di analisi di un programma compilato, ovvero di un binario eseguibile, per comprendere la sua logica di funzionamento e le sue caratteristiche interne. L'obiettivo può essere variabile: dalla ricerca di vulnerabilità di sicurezza, alla comprensione di algoritmi proprietari, fino alla modifica del software per aggiungere nuove funzionalità o per garantire la compatibilità con altri sistemi.
I due principali approcci al reverse engineering sono
- approccio statico, spesso con l'ausilio di un disassemblatore o un decompilatore, si tratta di interpretare il codice macchina del programma e provare a capire staticamente il funzionamento,
- approccio dinamico, ovvero eseguire il programma in un ambiente controllato, con l'ausilio di un debugger, un analizzatore di rete oppure altri strumenti per analizzarne il comportamento.
Vediamo adesso alcuni strumenti di base che ci permettono di fare delle analisi preliminari sui file eseguibili.
Trovare le informazioni di base di un binario
Con lo strumento file possiamo identificare delle proprietà di base di un eseguibile, ad esempio sul binario ls restituisce questo output.
$ file /usr/bin/ls
/usr/bin/ls: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
BuildID[sha1]=7aa8f52223e371fb77314d9a363129574096093b, for GNU/Linux 4.4.0, stripped
Ci restituisce delle informazioni come il fatto che è un eseguibile x86 a 64 bit, il linking è dinamico e che è stripped, ovvero non contiene informazioni di debug.
Possiamo visualizzare quali librerie sono caricate dinamicamente tramite il comando ldd.
$ ldd /usr/bin/ls
linux-vdso.so.1 (0x00007022fc02e000)
libcap.so.2 => /usr/lib/libcap.so.2 (0x00007022fbfc8000)
libc.so.6 => /usr/lib/libc.so.6 (0x00007022fbddc000)
/lib64/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007022fc030000)
Trovare le stringhe nei binari
Spesso le costanti stringhe sono inserite nei binari a certi indirizzi, e possono essere trovate tramite lo strumento strings.
Ad esempio queste sono alcune stringhe interessanti che si possono trovare nel binario ls.
$ strings /usr/bin/ls
/lib64/ld-linux-x86-64.so.2
_ITM_deregisterTMCloneTable
__gmon_start__
_ITM_registerTMCloneTable
__libc_start_main
__cxa_finalize
__cxa_atexit
strcmp
stdout
__overflow
fwrite_unlocked
[...]
cannot access %s
OWNER@
GROUP@
EVERYONE@
cannot read symbolic link %s
cannot open directory %s
reading directory %s
closing directory %s
[...]
Nel primo blocco si possono notare delle stringhe probabilmente usate per la risoluzione dinamica delle funzioni di libreria, mentre nel secondo blocco ci sono delle stringhe di formattazione, probabilmente usate in funzioni printf o simili.
Tracciare le system call
Una system call, o chiamata di sistema, è un meccanismo che permette ai programmi in esecuzione di interagire con il sistema operativo. Quando un'applicazione deve eseguire operazioni che richiedono l'accesso alle risorse hardware o ai servizi di sistema, come la gestione dei file, la comunicazione di rete o la gestione della memoria, utilizza le system call per richiedere tali servizi al kernel del sistema operativo. Sapere quali system call vengono chiamate da un processo può quindi darci delle informazioni su cosa sta facendo un programma.
Tracciare quali system call vengono eseguite da un processo è possibile in ambiente linux tramite lo strumento strace.
Ad esempio possiamo provare a lanciarlo sul programma ls.
strace ls
L'output sarà composto da tutte le system call invocate dal programma ls.
$ strace ls
execve("/usr/bin/ls", ["ls"], 0x7ffc85430f10 /* 52 vars */) = 0
[...]
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0), ...}) = 0
write(1, "main main.c\n", 13main main.c
) = 13
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
In particolare possiamo notare la prima chiamata execve per eseguire il processo ls, la chiamata a fstat per ottenere informazioni sui file relativi alla cartella corrente, e write per stampare in output i nomi dei file.
strace ci mostra anche i parametri delle chiamate e i valori di ritorno.
Questo può essere uno strumento molto utile per ottenere una informazione ad alto livello del comportamento del programma.
Esiste un programma molto simile che traccia però le chiamate a funzione a librerie caricate dinamicamente, chiamato ltrace.
Reverse engineering tramite Ghidra
Ghidra è un software di reverse engineering sviluppato dall'Agenzia per la Sicurezza Nazionale degli Stati Uniti (NSA) e reso pubblico nel 2019. Questo strumento open-source è stato progettato per analizzare file binari eseguibili ci può aiutare a comprendere il funzionamento interno di un software senza avere accesso al suo codice sorgente. Ghidra offre molte funzionalità, tra cui un disassemblatore e un decompilatore, ovvero un componente che prova a ricostruire un codice equivalente simile a c, che facilitano la comprensione della logica interna dell'eseguibile. Il software può essere scaricato dal sito ufficiale del progetto.
Analisi di un semplice programma
Prendiamo come esempio questo programma scritto in c.
#include <stdio.h>
int check(char* s) {
if (s[0] != 'g')
return -1;
if (s[1] != 'o')
return -1;
if (s[2] != 'o')
return -1;
if (s[3] != 'd')
return -1;
return 0;
}
int main (){
char buf[4];
scanf("%4s", buf);
if (check(buf) == 0) {
puts("OK");
} else {
puts("NOPE");
}
return 0;
}
Questo programma prende in ingresso una stringa da quattro caratteri, ed esegue un controllo, se è esattamente good allora stampa OK, altrimenti stampa NOPE.
Dal codice sorgente è molto facile capire il suo funzionamento, se proviamo a compilare e a guardare il codice assembly potrebbe essere molto complicato capire la logica.
Ghidra ci può aiutare proprio in questo.
Per prima cosa apriamo Ghidra e importiamo il file binario.
Una volta aperto ci verrà chiesto se vogliamo analizzare il file, e clicchiamo su sì.
A questo punto possiamo navigare tra le funzioni, e cliccare la funzione main.
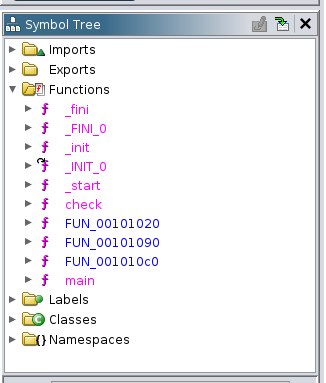
Nelle finestre principali, abbiamo sulla sinistra il disassemblatore, e sulla destra un tentativo di decompilazione della funzione main.
In realtà, a parte i nomi delle variabili il risultato della compilazione non è affatto male, ed è possibile capire cosa sta accadendo.
In particolare si vede che viene chiamata la funzione scanf e la funzione check.
Il risultato della funzione check viene poi confrontato con 0, e viene chiamata la funzione puts di conseguenza.
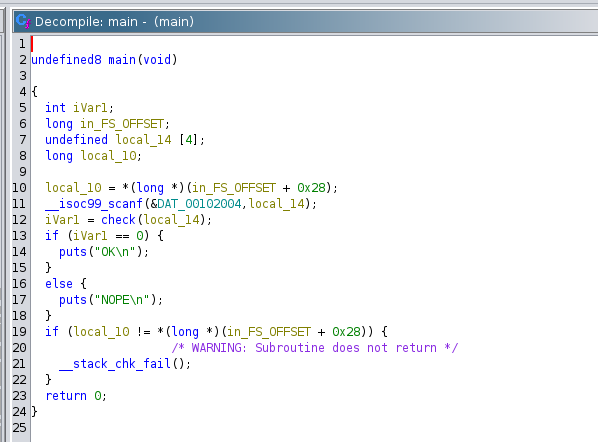
La funzione check è stata decompilata in maniera abbastanza strana, ma ci si può accorgere che ritorna 0 solo se la stringa in ingresso è proprio good.

Si può rinominare le variabili cliccandoci sopra con il tasto destro, e scegliendo "rename variable", oppure premendo L, così avremo un decompilato più pulito.
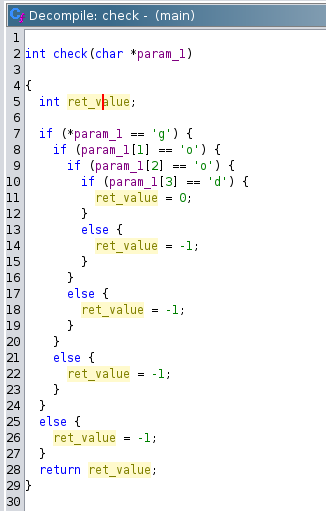
Si può quindi iterativamente migliorare la decompilazione rinominando variabili e funzioni e aggiungendo informazioni di tipo su array e strutture. Per approfondimenti sull'utilizzo di Ghidra si rimanda alla documentazione ufficiale.
Grazie a questi strumenti è possibile capire la logica interna di binari, in generale questo dovrebbe essere un argomento decisamente forte che si oppone al basare delle scelte di sicurezza sul fatto che un binario sia difficile da analizzare, come per esempio accadeva con i software che implementavano un algoritmo nascosto per controllare che l'utente avesse una licenza valida. Se questo algoritmo era presente nel binario, era solo questione di tempo prima che venisse analizzato e si potessero generare nuove chiavi, rendendo il controllo completamente inutile. Questo può essere visto anche come un esempio del fatto che security through obscurity (ovvero basare alcune scelte di sicurezza sul fatto che alcune componenti sono nascoste) spesso non costituisce un buon approccio, e dobbiamo sempre assumer che un attaccante abbia a disposizione tutto ciò di cui ha bisogno.
Corruzione della memoria
La corruzione di memoria accade quando un programma sovrascrive aree di memoria in maniera non intenzionale nell'intenzione originale. Ad esempio si potrebbero poter modificare variabili in maniera non attesa, possibilmente invalidando delle invarianti del programma e causando comportamenti imprevedibili del software, inclusi crash del programma. Le cause comuni della corruzione di memoria includono l'uso improprio di puntatori, buffer overflow, e problemi di gestione della memoria dinamica. Il problema della corruzione di memoria è particolarmente critico nei linguaggi di programmazione che non offrono una gestione automatica della memoria e che offrono una gestione diretta dei puntatori, come C e C++.
In questo capitolo vengono analizzate alcune più comuni tipologie di corruzione della memoria, e come possono essere sfruttate da un attaccante per causare comportamenti inaspettati del programma, fino ad arrivare all'esecuzione di codice arbitrario nel contesto del programma.
Buffer overflow
Un buffer overflow si verifica quando un programma scrive in un buffer più dati di quanti ne possa contenere, sovrascrivendo la memoria adiacente. Ad esempio, prendiamo questo codice c.
#include <unistd.h>
#include <stdio.h>
#include <string.h>
struct user {
char name[32];
char password[32];
};
int main() {
struct user u1;
strcpy(u1.password, "secret_password");
// leggi il nome utente
scanf("%64s", u1.name);
printf("nome: %s\npassword: %s\n", u1.name, u1.password);
}
Questo codice prende in ingresso un nome utente e stampa il nome utente e la password. Infatti inserendo un nome utente ci viene restituito il seguente output.
$ ./main
pippo
nome: pippo
password: secret_password
In qualche modo, è possibile che l'utente modifichi la password?
Proviamo a mandare in ingresso 32 caratteri A seguiti da 32 caratteri B.
$ ./main
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
nome: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
password: BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
La password è cambiata, anche se la funzione scanf dovrebbe scrivere su u1.name. Il bug si trova nel fatto che scanf accetta 64 bytes, ma il buffer è composto da 32 bytes.
La funzione scanf, però, non ha modo di sapere quanto sia grande il buffer, e scrive anche nella regione di memoria adiacente, che contiene proprio password.

Inoltre, abbiamo anche un secondo bug! La funzione scanf piazza un null byte \x00 alla fine della stringa come terminazione, ma lo piazza solo alla fine, dopo tutti i caratteri.
Questo null byte viene posizionato proprio un byte dopo password!
Possiamo vederlo tramite questo esempio leggermente modificato.
#include <unistd.h>
#include <stdio.h>
#include <string.h>
struct user {
char name[32];
char password[32];
unsigned long token;
};
int main() {
struct user u1;
strcpy(u1.password, "secret_password");
u1.token = 0x0123456789ABCDEF;
// leggi il nome utente
scanf("%64s", u1.name);
printf("nome: %s\npassword: %s\ntoken: %p\n", u1.name, u1.password, u1.token);
}
Come al solito, se inseriamo un nome corto il programma esegue quello che ci aspettiamo.
$ ./main
pippo
nome: pippo
password: secret_password
token: 0x0123456789abcdef
Ma se proviamo a inserire l'input precedente, possiamo notare che il primo (l'ultimo perché il numero è interpretato in formato little endian) è stato modificato in un null byte, al posto di ef.
$ ./main
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
nome: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
password: BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
token: 0x0123456789abcd00
Buffer overflow sullo stack
Un caso molto particolare e interessante per i bug di tipo buffer overflow è quando il buffer si trova sullo stack.
Infatti, all'interno dello stack ci sono alcune informazioni interessanti, quali le altre variabili locali della funzione, altri metadati per il record di attivazione e l'indirizzo di ritorno, ovvero l'indirizzo dell'istruzione a cui la funzione deve saltare quando ritorna.
Questo è tipicamente implementato tramite l'istruzione ret, che fa una operazione di pop dallo stack, e salta all'indirizzo letto.
Ad esempio prendiamo la seguente funzione c.
#include <stdio.h>
int main() {
char name[32];
scanf("%64s", name);
printf("ciao %s\n", name);
}
Il record di attivazione della funzione main è composto dal buffer name, e poco più in basso si trova l'indirizzo di ritorno della funzione main.
Una vulnerabilità di tipo buffer overflow (che è presente nel programma) ci potrebbe permettere di sovrascrivere questo indirizzo di ritorno e saltare a un indirizzo arbitrario di memoria di nostro controllo.
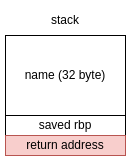
Infatti, inserendo un input più grande di 32 bytes, è possibile andare a sovrascrivere questo indirizzo di ritorno e causare un segmentation fault.
$ ./main
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ciao AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
[1] 1258251 segmentation fault (core dumped) ./main
Tramite un debugger come gdb è possibile verificare che il programma ha tentato di eseguire una ret all'indirizzo 0x4141414141414141 (corrispondente a otto byte di A), ma questo non è mappato nel processo, causando un segmentation fault.
0x55555555518d <main+68> ret <0x4141414141414141>
Manipolando opportunamente l'input è possibile far saltare il programma a un indirizzo specifico, prendendo così il controllo del flusso di esecuzione e portando nella maggior parte dei casi alla possibilità di eseguire codice arbitrario.
Corruzione dello Heap
L'allocazione dinamica della memoria in C e C++ viene gestita manualmente, attraverso l'uso di funzioni come malloc e free in C, e operatori come new e delete in C++.
Ogni richiesta di memoria all'allocatore ci restituisce un puntatore, e una regione di memoria grande quanto richiesta.
L'allocatore assume implicitamente che il programma utilizzerà solo quella porzione di memoria, e non andrà a scrivere in altre porzioni limitrofe.
Se questo dovesse accadere, si ha una istanza di corruzione della memoria dell'heap, e nonostante non sia facile da sfruttare come ad esempio un buffer overflow sullo stack, può nel peggiore dei casi portare a esecuzione di codice arbitrario.
Inoltre, la chiamata a free libera il blocco, e ci possono essere delle corruzioni anche derivanti dal fatto che il blocco di memoria sia utilizzato anche dopo la chiamata free, oppure che sia liberato più volte.
Vediamo adesso i bug più comuni che portano alla corruzione della memoria dell'heap.
Buffer overflow
Anche in questo caso, viene allocato un buffer, e una cattiva gestione dei limiti di questo buffer può portare alla scrittura in zone limitrofe. Infatti, spesso le regioni di memoria allocate sono limitrofe, e potremmo riuscire a scrivere in un buffer limitrofo. Questo però non è l'unico impatto che può avere un buffer overflow. Infatti l'allocatore, in particolare quello di GNU libc, la libreria standard più usata nei sistemi Linux, utilizza alcune porzioni di memoria tra i blocchi allocati per mantenere dei metadati, utilizzati ad esempio per sapere quanto è grande il prossimo blocco allocato. La scrittura di questi metadati può forzare l'allocatore dei comportamenti inaspettati, e nel peggiore dei casi può portare all'esecuzione di codice arbitrario.
Use after free (UAF)
Questo bug deriva dal fatto che stiamo utilizzando un puntatore non più valido (un cosiddetto dangling pointer) perché la memoria è già stata liberata. L'allocatore quando viene liberato un blocco scrive al suo interno dei metadati che verranno utilizzati per delle sue logiche interne di gestione della memoria libera. L'allocatore assume quindi che quella regione di memoria non verrà più sovrascritta dal programma, ma ovviamente non c'è nessun meccanismo di prevenzione della scrittura, quindi un bug di tipo use after free potrebbe andare a corrompere questi metadati.
Double free
Questo bug si verifica quando viene chiamata per due (o più) volte la funzione free sullo stesso puntatore.
Anche in questo caso, possiamo andare a forzare dei comportamenti inaspettati nella logica dell'allocatore.
Come sfruttare queste vulnerabilità
Queste tipologie di bug sono sfruttabili solo avendo una conoscenza profonda di come funziona internamente l'allocatore, e in generale non è banale ottenere esecuzione arbitraria. Inoltre, siccome sono dipendenti dalla logica dell'allocatore, dipendono anche dalla versione della libreria standard che stiamo usando. Tuttavia, questa tipologia di bug è molto comune nei software moderni e, come detto in precedenza, il fatto che un bug sia difficile da sfruttare non significa che sia impossibile. Ci sono svariate tecniche che si possono trovare per sfruttare questi bug, ad esempio una raccolta si può trovare a questa pagina, e l'argomento è anche d'interesse accademico per capire come rendere più sicure le implementazioni degli allocatori. Infatti col passare del tempo sono state inserite parecchie mitigazioni nella libreria standard per le vulnerabilità comuni, che rendono più difficile sfruttare questi bug.
Mitigazioni
Una mitigazione è una tecnica o una misura implementata per ridurre il rischio e l'impatto di bug di sicurezza in un sistema, rendendo più difficile il loro sfruttamento da parte di attaccanti. Sebbene le mitigazioni siano una componente fondamentale per la sicurezza, non costituiscono una soluzione definitiva, poiché non eliminano le vulnerabilità sottostanti. A volte infatti possono rendere una vulnerabilità non sfruttabile, ma per ogni mitigazione esiste comunque una tecnica in grado di aggirarla. Questo chiaramente richiede di aumentare la sofisticazione degli attacchi oppure di sfruttare altri bug e combinarli.
In questo capitolo vediamo alcune delle mitigazioni importanti che sono state implementate nel corso del tempo nei sistemi moderni.
NX - Non Executable
NX, che sta per "Non-executable data", è una mitigazione presente su molti processori moderni, e previene l'esecuzione di regioni di memoria su cui ci sono scritti dei dati come se fossero codice eseguibile. Infatti, una delle tecniche più usate per sfruttare ad esempio un buffer overflow sullo stack era quella di scrivere del codice macchina all'interno del buffer, e scrivere l'indirizzo dello stack corrispondente all'inizio nel valore di ritorno.
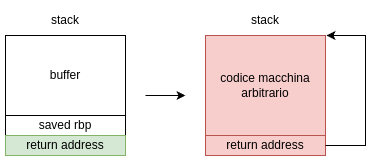
Quando la funzione eseguiva l'istruzione ret, il processore saltava all'interno dello stack, eseguendo proprio le istruzioni che erano state inserite dall'utente.
Infatti, il processore non ha nessun modo di discernere da quello che è codice e dati, perché entrambi sono memorizzati in RAM.
Grazie al supporto hardware del processore e del gestore della memoria, è possibile marcare le pagine di memoria virtuale con dei permessi, in particolare permessi di lettura, scrittura ed esecuzione. Se il processore prova a eseguire delle istruzioni da una memoria che non ha permessi di esecuzione, emetterà una eccezione, che risulterà molto probabilmente in un segmentation fault. Il codice viene mappato con i permessi di lettura e di esecuzione, mentre i segmenti che contengono dati, come lo stack e lo heap, vengono mappati con permessi di lettura e scrittura, ma non di esecuzione. In particolare, l'esempio sopra non potrà più funzionare, perché quando il processore proverà a eseguire la prima istruzione sullo stack, lancerà una eccezione.
Questa mitigazione può essere aggirata tramite una tecnica che si chiama Return Oriented Programming (ROP), che si basa sul non eseguire direttamente codice arbitrario, ma utilizzare "gadgets" già esistenti all'interno del binario e concatenarli per ottenere esecuzione di codice arbitrario.
Il canary
Le vulnerabilità di tipo buffer overflow sullo stack sono molto comuni, per ciò per evitare di renderle facilmente sfruttabili negli anni si è sviluppata una mitigazione che cerca di limitarne i danni. L'idea di base è che in presenta di buffer overflow, un attaccante per poter corrompere l'indirizzo di ritorno della funzione deve sovrascrivere anche tutti i byte precedenti, quindi possiamo piazzare un valore "sentinella" pseudo-casuale (non conosciuto da un attaccante) prima dell'indirizzo di ritorno della funzione, e al termine della funzione controllare che questo valore non sia stato modificato. Se il programma si accorge che il valore è stato modificato, termina immediatamente l'esecuzione, rendendo vano ogni attacco. Il termine canary deriva dall'analogia di questa tecnica con i canarini utilizzati nelle miniere per l'identificazione di gas tossici.
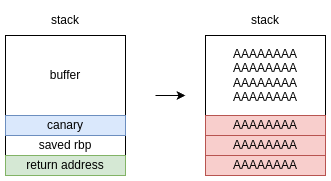
Prendiamo come esempio il programma vulnerabile a buffer overflow visto nel capitolo precedente.
#include <stdio.h>
int main() {
char name[32];
scanf("%64s", name);
printf("ciao %s\n", name);
}
Se proviamo a compilarlo con il canary attivo (gcc applica questa mitigazione per default) e proviamo a inserire un input lungo, non otteniamo più segmentation fault, ma otteniamo un altro errore.
$ ./main
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ciao AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
*** stack smashing detected ***: terminated
[1] 2592424 IOT instruction (core dumped) ./main
In particolare il programma è terminato prima che venisse eseguita l'istruzione ret con un valore di ritorno controllato dall'utente.
Possiamo andare a controllare il codice assembly del programma, e possiamo notare che sono state inserite nella funzione main delle istruzioni all'inizio
1161: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
1168: 00 00
116a: 48 89 45 f8 mov QWORD PTR [rbp-0x8],rax
e alla fine della funzione.
11ab: 48 8b 55 f8 mov rdx,QWORD PTR [rbp-0x8]
11af: 64 48 2b 14 25 28 00 sub rdx,QWORD PTR fs:0x28
11b6: 00 00
11b8: 74 05 je 11bf <main+0x66>
11ba: e8 71 fe ff ff call 1030 <__stack_chk_fail@plt>
11bf: c9 leave
11c0: c3 ret
Non è importante capire esattamente il codice, ma possiamo notare che all'inizio viene scritto sullo stack un valore (il canary), e poi alla fine prima di eseguire leave e ret viene letto lo stesso valore sullo stack e comparato con quello che è stato scritto all'inizio.
Se il valore del canary non corrisponde a quello che dovrebbe essere, viene chiamata la funzione __stack_chk_fail, che stampa il messaggio di errore stack smashing detected e termina il programma.
Questa mitigazione può essere aggirata tramite varie tecniche.
- Questa mitigazione si basa sul fatto che l'attaccante non può conoscere il valore del canary, ma potremmo avere una ulteriore vulnerabilità che ci permette di leggere valori arbitrariamente sullo stack. In questo caso sarebbe possibile leggere il valore del canary e quindi inserirlo nella giusta posizione in modo che il controllo non fallisca.
- Potremmo non essere in presenza di un buffer overflow, ma di una vulnerabilità che permette di scrivere ad offset arbitrari da un punto sullo stack, e se non vengono fatti i controlli adeguati potremmo scrivere direttamente dopo il canary sull'indirizzo di ritorno, lasciandolo invariato.
ASLR
Una delle mitigazioni più comuni presenti in tutti i sistemi operativi moderni è ASLR (Address Space Layout Randomization). Questa tecnica viene applicata quando il kernel carica un programma in memoria, randomizzando l'indirizzo di base dello stack, dello heap e se possibile anche dei binari caricati in memoria. Questo rende molto difficile per un attaccante conoscere esattamente l'indirizzo di oggetti o funzioni in memoria. Ad esempio, nel caso in cui un attaccante sia riuscito a prendere il controllo di un indirizzo di ritorno, non sapere a che indirizzo sono collocate le funzioni dell'eseguibile potrebbe permettergli di saltare a pezzi di codice utili per portare avanti l'attacco. ASLR è stato per la prima volta introdotto in Linux nel 2005 e successivamente adottata da altri sistemi operativi.
ASLR è una mitigazione molto potente, ma può essere aggirata con varie tecniche.
- Se abbiamo una vulnerabilità che ci rivela un puntatore valido, possiamo derivare (esattamente o approssimativamente) altri puntatori ad altri oggetti utili. Questo perché solamente l'indirizzo di base delle porzioni di memoria viene randomizzato, mentre gli offset relativi tra gli oggetti non possono essere randomizzati altrimenti non sarebbe più possibile eseguire il programma.
- Nel caso specifico dell'implementazione del kernel Linux, i bit di entropia che offre la randomizzazione degli indirizzi è relativamente bassa, e in alcuni contesti specifici potrebbe essere suscettibile a un attacco bruteforce.
Argomenti avanzati
In questo capitolo vediamo alcuni accenni ad argomenti e tecniche avanzate. Verranno presentati per prima degli attacchi che si possono effettuare non a programmi ma direttamente al kernel del sistema operativo. Infine, verranno presentati alcuni attacchi che si basano su debolezze o bug presenti a livello hardware nella CPU o in altri componenti che compongono il computer.
Attacchi a livello kernel
Il kernel di un sistema operativo è una componente fondamentale per ogni sistema informatico. Esso infatti si occupa, tra le altre cose, dell'interazione con l'hardware e della gestione dei processi e della memoria. Si occupa inoltre di effettuare controlli di sicurezza quando ad esempio accediamo a un file oppure utilizziamo un dispositivo hardware, a seconda del grado di privilegio dell'utente che ha iniziato la richiesta. Ad esempio supponiamo di avere un server a cui possono accedere più utenti: il kernel si occuperà di controllare che i vari utenti possano accedere solo ai file su cui hanno i permessi, e che non possano interagire con file o processi di altri utenti o del sistema.
Il kernel esegue del codice al privilegio massimo, il cosiddetto "ring 0", e può accedere liberamente a hardware e a tutta la memoria fisica. I processi tipicamente vengono eseguiti a "ring 1", e hanno bisogno di fare chiamate al kernel per accedere all'hardware. Questo viene fatto tipicamente tramite l'utilizzo di system call, oppure con meccanismi analoghi.
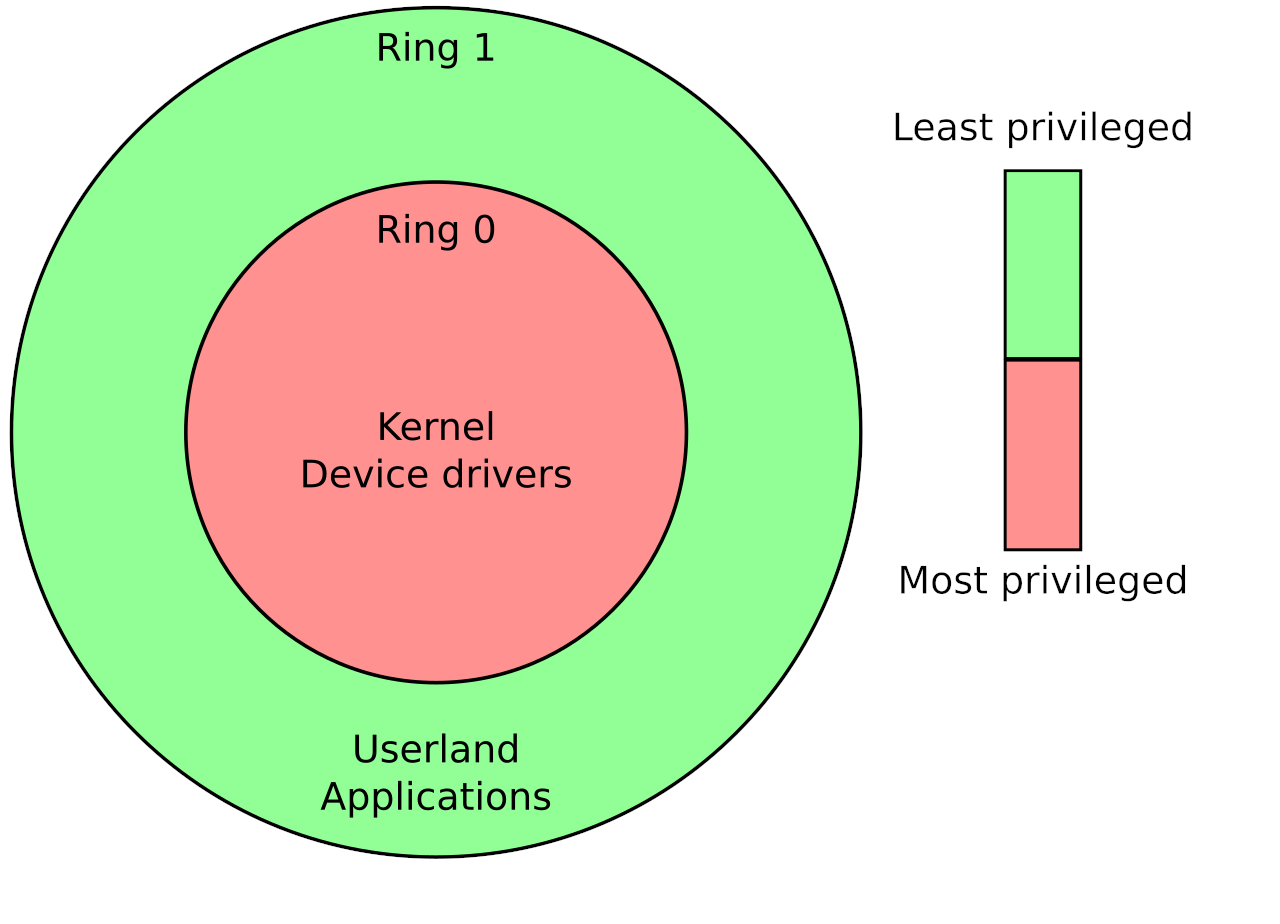
Il kernel, però, è un componente come gli altri e può anche esso contenere bug che possono portare alla corruzione della memoria. Bisogna osservare che se un bug porta all'esecuzione di codice arbitrario nel contesto del kernel, questo codice viene eseguito al livello di privilegio massimo, e possiamo fondamentalmente aggirare ogni tipo di protezione sulle risorse di sistema. Uno degli scopi principali di un attacco a livelli kernel potrebbe essere elevare il grado di privilegio del proprio processo, questo tipo di attacco viene definito Local Privilege Escalation (LPE). Presuppone di avere la possibilità di eseguire un programma su una macchina in maniera non privilegiata; sfruttando una o più vulnerabilità presenti nel kernel il programma riesce a modificare la struttura contenuta nella memoria kernel che contiene le informazioni riguardanti il suo processo e a elevare i suoi privilegi. Nella pratica, un tipico risultato di questo tipo di attacco potrebbe essere far ottenere una shell di root a un utente non privilegiato.
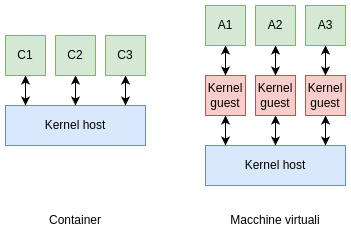
Questo tipo di attacchi è particolarmente rilevante in ambiente cloud, dove si tende sempre si più a isolare i processi e le applicazion tramite l'utilizzo di container come Docker. Una delle caratteristiche cruciali che differenzia l'utilizzo di container dall'utilizzo di macchine virtuali è il fatto che i container condividono lo stesso kernel host. Un'applicazione che viene eseguita in un container, se riesce a effettuare un attacco di tipo Local Privilege Escalation, può ottenere i privilegi di root nella macchina host, e quindi accedere anche ai dati e i processi degli altri container in esecuzione. Un attacco analogo esiste anche nel contesto delle macchine virtuali, ma si basa sullo sfruttare vulnerabilità presenti nell'hypervisor della macchina virtuale. Tali tipi di attacchi dove si riesce a eseguire codice arbitrario nella macchina host dal guest si chiamano Virtual Machine Escape.
Speculative execution e bug hardware
I processori moderni, per migliorare le prestazioni, possono decidere di eseguire in anticipo alcune istruzioni che probabilmente dovranno eseguire in futuro, invece che aspettare tempi morti. Se il l'algoritmo di predizione aveva ragione abbiamo un incremento delle performance, altrimenti si buttano via i risultati e si va avanti come se nulla fosse successo, ma senza neanche aver perso tempo.
Anche se l'algoritmo di predizione funziona nel 50% dei casi (come ad esempio un algoritmo completamente randomico) si ha un significativo miglioramento delle prestazioni!
Questo modo di operare basato su una scommessa si chiama esecuzione speculativa, in quanto appunto il processore specula sul risultato di quelle istruzioni che possono andare a modificare il flusso di esecuzione del programma, come ad esempio:
- salti condizionati
- chiamate a funzione
- ritorno dalle funzioni
in modo da ottenere un significativo miglioramento delle performance.
Meltdown & Spectre
Nel Gennaio del 2018 due vulnerabilità vengono rese note: Meltdown e Spectre. Sono entrambe vulnerabilità che riguardano l'esecuzione speculativa di praticamente tutti i processori dell'epoca, anche se di produttori diversi.
Meltdown permette ad un processo di leggere la memoria di altri processi, questo accade perché il codice che viene eseguito in maniera speculativa può accedere a tutti gli indirizzi di memoria, anche a quelli non direttamente associati al processo. Questo attacco permette quindi di estrarre tutti i segreti dagli altri processi, ma anche dal kernel!
Spectre al contrario si basa sulla possibilità di far eseguire, ad un altro processo, codice arbitrario durante l'esecuzione speculativa. Anche in questo modo si può forzare l'estrazione di segreti appartenenti all'altro processo, che può anche essere lo stesso kernel.
Attacchi side-channel
Entrambi gli attacchi metdown e spectre non permettono di estrarre dati direttamente. Quello che fanno è usare i dati per eseguire degli accessi alla memoria cache in maniera dipendente dal dato letto. L'attaccante successivamente, per poter estrarre i dati davvero, è costretto a misurare i tempi di accesso alla memoria:
- se i tempi sono bassi allora probabilmente il codice speculativo vi ha acceduto
- se i tempi sono alti, probabilmente il codice non vi ha acceduto.
Questa tecnica è nota come FLUSH+RELOAD ed è utilizzata spesso in questo genere di attacchi.
Più in generale qualsiasi tecnica che permette di ottenere informazioni in maniera indiretta è detto attacco side-channel. Alcuni esempi ricorrenti di side-channel sono:
- timing attacks: misurare il tempo di esecuzione di un software o una routine permette spesso di ottenere informazioni sul risultato della computazione
- power monitoring: monitorare la potenza dell'hardware a volte può essere utile a capire cosa sta facendo, sia per il consumo stesso che per il rumore che l'hardware può aggiungere sul canale di alimentazione