Introduzione alla sicurezza
In questo modulo vedremo cosa si intende per sicurezza informatica e cosa rende sicuro un sistema. Analizzeremo poi alcuni principi che possono aiutarci nello sviluppo sicuro del software.
Assets e minacce
Il termine "sicurezza informatica" è spesso usato in modo impreciso e fumoso. La definizione che ci dà il NIST è la seguente:
[La sicurezza è] l'assenza di condizioni che possono causare la perdita di asset con conseguenze irreparabili.
Per definire l'ambito della sicurezza dobbiamo quindi rispondere innanzitutto a delle domande:
- Chi siamo come organizzazione/azienda e che servizio vogliamo offrire?
- Quali sono gli asset da proteggere?
- Chi può essere interessato a danneggiare i nostri asset?
- Quali sono le conseguenze della perdita o del danneggiamento di tali asset?
Vediamo adesso nel dettaglio cosa significano queste cose.
Asset
In generale possiamo definire un asset come un oggetto che ha valore per l'organizzazione o per l'azienda. Un asset può essere
- tangibile, ad esempio un oggetto fisico come un server, un dispositivo di rete, un firmware,
- intangibile, ad esempio dei dati riservati, software, proprietà intellettuale o reputazione.
Definire un asset significa anche associare a esso delle conseguenze associate per la sua perdita o danneggiamento. Ad esempio la perdita di infrastruttura critica a causa di un attacco potrebbe causare una interruzione dell'erogazione del servizio. Capire quali sono le conseguenze del danneggiamento dei vari asset ci permette di identificare quai sono gli asset critici per conseguire i nostri obiettivi, e ci fa creare una protezione adatta per provvedere alla sicurezza dei sistemi.
Threat actors
Si parla di threat actor (tradotto in italiano attori di minaccie) quando si vuole descrivere qualunque soggetto, individuale o no, che è intenzionato a danneggiare i nostri sistemi digitali. Le motivazioni di un attaccante possono essere molteplici, di seguito viene riportato qualche esempio.
- Divertimento, dei soggetti potrebbero provare ad attaccare un sistema solo per il gusto di sapere che può essere fatto.
- Fama, un soggetto può cercare di attaccare un sistema per ottenere notorietà per le sue skill tecniche.
- Attivismo, il risultato dell'attacco può essere di pubblicare un messaggio (tipicamente politico) o danneggiare un'organizzazione o azienda non allineata con gli ideali dell'attaccante.
- Guadagno, in qualche modo il soggetto trae guadagno dall'attacco.
- Coercizione, un soggetto attacca un sistema per far compiere alla vittima una azione che non vorrebbe compiere.
Alcuni dei profili di potenziali attaccanti potrebbero essere hobbysti e ricercatori, governi, attori criminali, tool automatizzati oppure persone interne all'organizzazione.
Errori comuni nel risk assessment
Di seguito sono riportati alcuni errori comuni che le organizzazioni o le aziende commettono nella valutazione del rischio dei propri sistemi.
Possono non realizzare di essere un bersaglio: potrebbe non essere immediatamente ovvio che vi siano degli asset che possono interessare a un potenziale attaccante, ma è il caso che molte aziende, seppur piccole o che non posseggono dati sensibili, hanno comunque degli asset che potrebbero essere utilizzati per compiere un attacco più grande. Per esempio l'accesso alla casella di posta di una piccola azienda potrebbe facilitare delle operazioni di phishing verso un'altra azienda, oppure semplicemente l'accesso a un server, seppur non comprometta l'organizzazione, potrebbe formire a un attaccante un indirizzo IP da cui lanciare un ulteriore attacco.
In generale gli attaccanti scelgono la via più veloce e economica. Anche se potrebbero essere capaci d'impiegare tecniche e metodi complessi, tipicamente gli attaccanti scelgono la via più semplice che soddisfa i propri bisogni. Per esempio molti utilizzano il phishing come principale vettore di raccolta d'informazioni. Nel design dei sistemi, bisogna assicurarsi di coprire i casi semplici, come ad esempio abilitare l'autenticazione a due fattori, prima di preoccuparsi di exploit esotici.
D'altra parte non si deve mai sottovalutare un attaccante, o in generale quanto un attaccante può spendere di risorse e tempo per attaccare un sistema.
Alcuni esempi degni di nota di attacchi estremamente sofisticati sono la recente backdoor in xz-utils oppure le backdoor inserite dall'NSA all'interno di router Cisco intercettati durante la spedizione.
Un altro errore tipico è il pensiero che anche se siamo attaccati, comunque possiamo risalire all'identità degli attaccanti. Non è sempre facile, innanzitutto perché esistono sistemi di anonimizzazione come Tor che non permettono di risalire alla vera sorgente dell'attacco. Inoltre, se stiamo parlando di un soggetto nazionale (ad esempio per portare a termine attacchi di tipo militare) potrebbe godere della protezione del governo locale. Inoltre, questo è un caso in cui gli attaccanti non hanno paura di essere trovati o catturatu, in quanto è proprio il governo locale che ha approvato l'attacco.
Vulnerabilità
Una vulnerabilità è un errore o una dimenticanza in un sistema che ne compromette la sicurezza. Questa è derivata da un bug nel sistema: in altre parole se un bug crea un rischio di sicurezza allora è una vulnerabilità. Un exploit è un programma o un metodo per sfruttare una vulnerabilità, che ci permette di compromettere un sistema. Molte delle vulnerabilità scoperte in software di interesse comunie sono documentate nel common vulnerabilities and exposures (CVE) database.
A ogni vulnerabilità viene assegnato uno score di severità (CVSS score), che tiene conto di alcune proprietà della vulnerabilità, come quale sia il vettore di accesso per sfruttarla (per esempio locale o remoto), la complessità di accesso, se richiede autenticazione al sistema e l'impatto sul sistema. Inoltre tiene conto di altre metriche quali la sfruttabilità (ad esempio se l'attacco è solo teorico oppure esistono exploit online) e se è possibile rimediarla o mitigarla.
A prima vista potrebbe sembrare che si possa raggiungere la correttezza completa, eliminando tutti i bug nel nostro sistema, quindi eliminando ogni possibile vulnerabilità. Questo però non è così semplice, per diverse ragioni:
- all'aumentare della complessità, il sistema diventa sempre più prono a contenere bug. Ad esempio se abbiamo due componenti che in isolamento non presentano bug, possono comunque emergere errori nell'interazione tra di essi.
- Tipicamente nei sistemi informatici si tende a utilizzare dipendenze fornite e sviluppate da terze parti. Queste potrebbero contenere bug che spesso sono fuori dal controllo degli sviluppatori che utilizzano queste dipendenze.
- I sistemi informatici si affidano molto spesso a sistemi legacy datati, che non vengono aggiornati per ridurre costi o possibili down time del servizio.
Ciclo di vita di una vulnerabilità
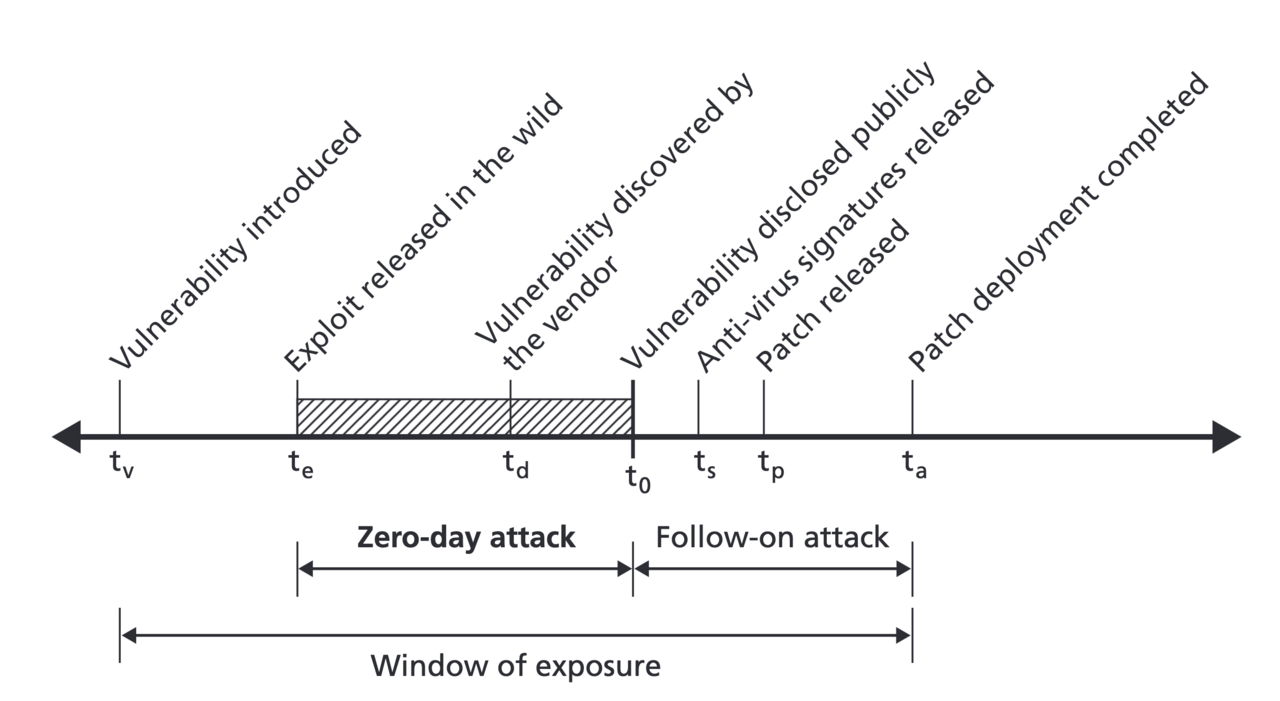
Una vulnerabilità viene introdotta in un sistema ad esempio con una modifica al codice che contiene un bug. In un successivo momento, qualcuno scopre la vulnerabilità, in questo stadio dove nessun altro la conosce si chiama zero-day. Questo tipo di vulnerabilità è molto potente, in quanto né il vendor né gli utilizzatori del sistema ne sono a conoscenza. Molte agenzie di intelligence, governi oppure organizzazioni criminali comprano vulnerabilità per i loro scopi, che siano lanciare attacchi, oppure memorizzarle per utilizzi futuri.
Una volta che il vendor scopre la vulnerabilità intercorre un lasso di tempo per creare una patch che la elimina. Questo però non è scontato: il vendor potrebbe non essere interessato a pubblicare una patch, potrebbe essere andato out-of-business, o la vulnerabilità potrebbe essere semplicemente non eliminabile.
Dopo che una patch è stata pubblicata, i sistemi che non hanno ancora aggiornato sono comunque esposti ad attacchi. L'esposizione di un sistema termina quando è stata applicata la patch che risolve quella vulnerabilità. In questo periodo di tempo, la vulnerabilità è chiamata one-day (o anche n-day) in quanto è pubblicamente nota, ma i sistemi non hanno ancora applicato la patch.
Proprietà CIA
Quando parliamo di sicurezza dei sistemi, in realtà quello che vogliamo garantire sono tre proprietà fondamentali:
- confidentiality, ovvero le informazioni sono accessibili solamente a soggetti autorizzati,
- integrity, ovvero le informazioni non sono state modificate o rimosse in maniera non autorizzata,
- availability, che possiamo tradurre in italiano con "disponibilità", ovvero il servizio è garantito senza interruzioni agli utenti legittimi.
Queste tre proprietà si chiamano comunemente "triade CIA" e, anche se altri modelli sono stati proposti, rimane un buon framework per analizzare la sicurezza dei sistemi informatici.
Confidenzialità
Per confidenzialità si intende "la proprietà che l'informazione non è resa disponibile o pubblicata a soggetti, entità o processi non autorizzati". Il concetto può sembrare simile a privacy, ma in realtà la confidenzialità è una componente della privacy di soggetti, che garantisce e protegge i dati personali da accessi non autorizzati.
Esempi di violazioni di confidenzialità possono essere
- esfiltrazione di dati personali degli utenti,
- email sensibili inviate a indirizzi errati,
- lettura di una chiave di cifratura da parte di un processo o un utente non autorizzato.
Integrità
Per integrità si intende la proprietà che l'informazione è accurata e completa per il suo intero ciclo di vita. Questo vuol dire che non può essere modificata senza che questo venga rilevato in qualche modo.
Esempi di violazioni di integrità possono essere:
- la modifica delle transazioni in un database bancario,
- la modifica di pacchetti in transito da un client a un server (ad esempio tramite attacchi man-in-the-middle),
- la modifica di regioni di memoria in un processo da parte di utenti o altri processi non privilegiati.
Disponibilità
Per disponibilità si intende la proprietà che un sistema svolga le proprie funzionalità correttamente qualora venga utilizzato da un utente. Questo implica che l'intero sistema deve funzionare correttamente. Questa proprietà è all'intersezione tra sicurezza e affidabilità: periodi di down time possono accedere anche senza avere subito nessun attacco, ma semplicemente per un malfunzionamento del software.
Esempi di violazioni di disponibilità possono essere:
- un'applicazione web che non è disponibile perché sta subendo un attacco di tipo DDoS (distributed denial of service)
- un'applicazione non raggiungibile per un fallimento dei dispositivi di rete
- la non disponibilità di un servizio perché il disco fisso del server risulta non avere spazio disponibile.
Superficie di attacco
Per superficie di attacco di un sistema informatico si intende la somma dei punti (anche chiamati "vettori di attacco") da cui un soggetto non autorizzato può interagire con il sistema. Ad esempio tutti i punti dove esiste l'input da utente, tutti i servizi esposti di un server oppure tutti i dispositivi accessibili fisicamente. Avere un buona comprensione della propria superficie di attacco presenta vari vantaggi:
- permette di capire quali funzioni o quali parti del sistema hanno bisogno di revisioni o test per le proprietà di sicurezza,
- permette di identificare aree di codice ad alto rischio che richiedono una attenzione particolare durante lo sviluppo,
- permette la semplificazione delle operazioni di audit, in quanto possiamo concentrarci sui punti di ingresso di un eventuale attaccante.
Ad esempio, per una applicazione web la superficie di attacco potrebbe essere composta da:
- tutti gli endpoint, con particolare attenzione per quelli di login/autenticazione
- header HTTP e cookie
- local storage
- eventuali API esposte
- file provenienti da sorgenti non fidati (ad esempio da un upload di un utente).
Spesso però esistono altri punti di ingresso meno ovvi, come
- altri servizi esposti pubblicamente (ad esempio il database oppure servizi di caching)
- interfacce o pannelli da amministratore,
- deployment di test.
Una regola generale è che la "security through obscurity" non è un buon metodo di approccio per gestire la sicurezza. In altre parole
Gestione della superficie di attacco
Come regola generale, tenere la superficie di attacco controllata e piccola è una buona pratica di sicurezza. Questo aiuta a controllare la complessità dell'applicazione e a semplificare le analisi di sicurezza. Per esempio potrebbe avere senso semplificare le interfacce o API delle funzionalità già esistenti, oppure disabilitare completamente delle funzionalità poco usate.
Quando si fa una modifica al sistema, per esempio viene aggiunto un endpoint, viene modificata la semantica di una funzionalità o altro, bisogna farsi alcune domande:
- Cosa è cambiato nell'applicazione?
- Quale componente è stato modificato e quanto questo componente è critico?
- Quali punti di ingresso può aver introdotto questa modifica?
Ad esempio, se abbiamo una applicazione web e aggiungiamo una pagina di documentazione statica, la superficie di attacco è sicuramente aumentata, ma non in modo significativo. In altre parole è probabile che prima e dopo la modifica, le possibilità di un attaccante sono fondamentalmente le stesse. Invece se aggiungiamo per la prima volta una funzionalità che richiede l'upload di un file da parte dell'utente, questo introduce un nuovo punto di ingresso, che deve essere attentamente valutato. Allo stesso modo modifiche alla gestione dell'autenticazione oppure alla gestione delle sessioni devono essere attentamente revisionate perché stanno impattando componenti critiche dell'applicazione.
Tenere la superficie di attacco piccola tende a ridurre gli errori di sicurezza, non è una vera e propria tecnica di mitigazione. Infatti non previene in nessun modo i danni che un attaccante può fare se una vulnerabilità viene scoperta.
Principi di design sicuro
In questo capitolo analizziamo alcuni principi generali che possono aiutarci a sviluppare software e sistemi resilienti ad attacchi.
Defense in depth
La defense in depth (tradotto alla lettera, difesa in profondità) è una strategia di sicurezza che impiega più strati di sicurezza per proteggere un asset di un'organizzazione. Si basa sull'idea che se uno strato di sicurezza dovesse cadere, comunque gli altri rimarrebbero a proteggere l'asset. L'obiettivo di defense in depth è di costruire sistemi che sono resilienti ad attacchi, e che sono in grado di reagire a incidenti in modo rapido e senza danni. Infatti, implementando più strati di sicurezza, siano essi di sicurezza fisica, sicurezza di rete o sicurezza delle applicazioni, si può ridurre il rischio di un attacco e limitare i danni che potrebbe indurre.
Ad esempio, supponiamo di avere una server per una applicazione web, possiamo avere vari livelli di sicurezza. Per prima cosa potremmo impostare un firewall di rete per limitare il traffico solo alle porte necessarie per il servizio. Inoltre potremmo esporre il servizio utilizzando solamente trasporto crittografato e sicuro, come su HTTPS. In un ambiente Cloud come AWS potrebbe essere utile inoltre impostare i Security Groups per controllare il traffico in entrata e in uscita. Infine, per una applicazione web potrebbe essere utile installare un Web Application Firewall (WAF) per identificare richieste potenzialmente malevole, e bloccare gli attacchi più comuni. In realtà, questo sistema rappresenta una mitigazione, e un attaccante esperto potrebbe comunque riuscire ad aggirarlo.
Un altro strato potrebbe essere la sicurezza del server, ad esempio impostare correttamente l'accesso al server con una password sicura o preferibilmente con una chiave. Inoltre, i processi all'interno del server dovrebbero essere eseguiti in maniera non privilegiata. Se disponiamo di più componenti (ad esempio un server web e un database) dovrebbero essere il più possibile separati, così che se viene compromesso uno dei componenti il danno sia limitato. Per questo potrebbe essere utile fare il deployment dei componenti tramite container, in questo modo è più semplice gestire i permessi di ogni componente e limitare i danni nel caso uno di questi venisse compromesso.
Impostare un buon sistema di monitoraggio e gestione dei log è una buona pratica, e ci permette di identificare anomalie o attività sospette. Potrebbe essere utile, inoltre, utilizzare software antivirus o dei software di identificazione delle intrusioni (IDS) per identificare degli accessi non autorizzati.
Questi sono solo alcuni esempi di come questo principio potrebbe essere messo in pratica. In generale dobbiamo chiederci, se questo componente venisse compromesso oppure questo sistema di sicurezza venisse aggirato, cosa un attaccante può fare? Una volta fatta questa domanda dobbiamo chiederci cosa possiamo fare per limitare i danni di tale attacco.
Least privileges
Il principio di least privileges (privilegi minimi) ci dice che a un utente o a un sistema devono essere dati solamente i privilegi per svolgere il suo lavoro o la sua funzione, e niente altro. Ad esempio a un utente, deve essere dato accesso solamente alle funzionalità che gli sono strettamente necessarie, e in questo modo si riduce la superficie di attacco e il rischio di accessi non autorizzati a funzionalità o dati privati. Allo stesso modo, a un componente dovrebbe essere dato il minimo grado di privilegio per svolgere la sua funzionalità.
Questo principio è strettamente legato a quello di separazione di responsabilità, ovvero diversi componenti hanno diverse responsabilità e gradi di privilegio. Questo riduce il rischio di avere un unico componente che ha controllo su tutto il sistema, risultando un punto molto sensibile e aumentando il rischio di danni se venisse compromesso da un attacco.
Zero trust networking
Il principio di Zero Trust è un modello di sicurezza che presuppone che nessun utente o dispositivo, sia all'interno che all'esterno della rete, debba essere considerato affidabile. Invece di concedere automaticamente l'accesso sulla base del fatto che per esempio un dispositivo è connesso alla rete interna, o sulla base di altre caratteristiche superficiali, è preferibile che tutti gli accessi siano verificati continuamente attraverso autenticazioni rigorose e autorizzazioni granulari.
Il principio è generale, ma in particolare si parla di Zero Trust Networking, che applica questi principi al livello della rete, enfatizzando che ogni tentativo di accesso ai dati o ai sistemi deve essere autenticato, autorizzato e criptato, indipendentemente da dove provenga il tentativo. Non è per esempio valido fidarsi di un dispositivo che accede dalla rete interna dell'organizzazione, in quanto questa potrebbe venire compromessa. Questo principio è sempre più importante nel mondo odierno, dove ci possono essere molti dispositivi connessi alla rete interna, e ognuno di questi potrebbe essere un potenziale vettore di attacco.
Per raggiungere zero trust networking può essere utile impiegare tecniche di microsegmentazione: questa è una tecnica di sicurezza di rete che suddivide una rete in segmenti più piccoli e isolati, ognuno dei quali ha politiche di sicurezza specifiche e personalizzate. Questo approccio permette un controllo granulare del traffico tra segmenti, riducendo la superficie di attacco e limitando il movimento laterale di potenziali intrusi all'interno della rete. Ogni segmento della rete richiede che gli accessi siano autenticati e autorizzati indipendentemente, seguendo il principio che nessuna richiesta, interna o esterna, sia considerata affidabile. Ad esempio, in un data center, i server di database, le applicazioni e le interfacce utente possono essere collocati in segmenti separati, con firewall e policy di accesso specifiche tra di essi. Questo garantisce che anche se un attaccante compromette una parte della rete, non può facilmente spostarsi e accedere ad altre risorse sensibili senza superare ulteriori barriere di sicurezza.
Analisi delle applicazioni
In questo capitolo, esploreremo tre tecniche fondamentali per identificare problemi e debolezze di sicurezza nel software: l'analisi statica, l'analisi dinamica e il fuzzing. L'analisi statica implica l'esame del codice sorgente senza eseguirlo, permettendo di individuare vulnerabilità tramite l'individuazione di pattern non sicuri. L'analisi dinamica, d'altra parte, comporta l'esecuzione del software in un ambiente controllato per monitorarne il comportamento, rilevando anomalie, errori di esecuzione o comportamenti inaspettati. Il fuzzing, una forma di analisi dinamica, consiste nell'invio di input casuali o malformati all'applicazione per provocare comportamenti imprevisti e crash, scoprendo così vulnerabilità non facilmente individuabili con altri metodi.
Analisi statica del codice sorgente
L'analisi statica di sicurezza è una metodologia utilizzata per esaminare il codice sorgente di un software senza eseguirlo, con l'obiettivo di identificare vulnerabilità e debolezze di sicurezza. Questa analisi viene tipicamente effettuata utilizzando strumenti automatici che scansionano il codice per rilevare pattern di codice pericolosi, errori di programmazione, e violazioni di best practice di sicurezza.
Le principali tecniche per eseguire l'analisi statica includono l'analisi sintattica per pattern noti che potrebbero portare a vulnerabilità (ad esempio di tipo buffer overflow oppure SQL injection), analisi del flusso di esecuzione o analisi delle librerie e delle dipendenze. Questi strumenti si possono estendere anche all'analisi di file di configurazione di Docker, script per Infrastructure as Code, e file di specifica per oggetti nel cloud, identificando i comuni errori di configurazione.
Una lista di strumenti utili all'analisi statica del codice sorgente può essere trovata su sito di owasp oppure sul sito del NIST.
Esempio di analisi statica
Prendiamo come esempio il seguente codice scritto in C++.
#include <iostream>
#include <cstring>
int f(int x) {
int buf[10];
memset(buf, 0, 10 * sizeof(int));
return buf[x];
}
int main() {
std::cout << f(42) << std::endl;
}
Questo codice prova a stampare l'elemento 42 di un array di soli 10 elementi. Proviamo ad analizzarlo con un tool di analisi statica per c++, ovvero cppcheck.
$ cppcheck --enable=all main.cpp
Checking main.cpp ...
main.cpp:7:12: error: Array 'buf[10]' accessed at index 42, which is out of bounds. [arrayIndexOutOfBounds]
return buf[x];
^
main.cpp:11:17: note: Calling function 'f', 1st argument '42' value is 42
std::cout << f(42) << std::endl;
^
main.cpp:7:12: note: Array index out of bounds
return buf[x];
Cppcheck ha identificato correttamente che stiamo accedendo all'array fuori dai bounds semplicemente analizzando il codice staticamente.
Pur essendo molto potenti, gli strumenti di analisi statica spesso utilizzano delle euristiche per identificare potenziali vulnerabilità nel codice, il che può portare alla generazione di alcuni falsi positivi e falsi negativi. Inoltre alcune vulnerabilità non possono essere identificate semplicemente analizzando staticamente il codice. Pertanto, sebbene possano essere utili per migliorare la sicurezza e la qualità del codice, non dovrebbero essere l'unica misura adottata e dovrebbero essere integrati con le altre tecniche di analisi e il testing manuale.
Analisi dinamica dell'applicazione
L'analisi dinamica di sicurezza delle applicazioni è una metodologia che richiede il test del software durante la sua esecuzione per rilevare bug o comportamenti anomali che potrebbero non essere evidenti dalla semplice analisi del codice sorgente. Inoltre, potremmo trovarci nello scenario in cui non si ha accesso al codice sorgente, quindi l'analisi statica viene automaticamente esclusa. Questo tipo di analisi viene tipicamente effettuato in un ambiente controllato e monitorato, spesso utilizzando strumenti come debugger, profiler e monitor di runtime. Gli strumenti di analisi dinamica possono anche eseguire test di penetrazione automatizzati per simulare attacchi reali e valutare come l'applicazione risponde a tali minacce.
L'analisi dinamica complementa l'analisi statica perché può rilevare vulnerabilità che emergono solo durante l'esecuzione dell'applicazione, o comunque sono più semplici da individuare dinamicamente. Ad esempio, problemi come race condition possono essere identificati facilmente solo quando il software è in esecuzione. Una analisi statica per rilevare problemi di concorrenza non è impossibile, ma è molto difficoltosa e spesso è difficile formalizzare il problema adeguatamente.
Esempio di analisi dinamica
Consideriamo il seguente codice scritto in c.
#include <stdio.h>
#include <stdlib.h>
int main() {
int* v = malloc(20);
malloc(256);
for(int i=0; i<20; ++i) {
v[i] = i;
}
for(int i=19; i>=0; i--) {
printf("%d -> %d\n", i, v[i]);
}
return 0;
}
Eseguendo il programma otteniamo il risultato che ci aspettiamo.
19 -> 19
18 -> 18
17 -> 17
16 -> 16
15 -> 15
14 -> 14
13 -> 13
12 -> 12
11 -> 11
10 -> 10
9 -> 9
8 -> 8
7 -> 7
6 -> 6
5 -> 5
4 -> 4
3 -> 3
2 -> 2
1 -> 1
0 -> 0
Questo programma, però, contiene un errore, ovvero la chiamata malloc alloca 20 bytes, ma l'array è in realtà grande 20 * sizeof(int) bytes, quindi nel primo ciclo for stiamo scrivendo fuori dai limiti del nostro blocco allocato.
Possiamo accorgerci di questo utilizzando uno strumento chiamato valgrind, che permette di identificare a tempo di esecuzione errori come scritture e letture in memoria non valide, allocazioni non rilasciate e molto altro.
Eseguendo valgrind sul programma abbiamo il seguente risultato.
$ valgrind ./main
==277855== Memcheck, a memory error detector
==277855== Copyright (C) 2002-2024, and GNU GPL'd, by Julian Seward et al.
==277855== Using Valgrind-3.23.0 and LibVEX; rerun with -h for copyright info
==277855== Command: ./main
==277855==
==277855== Invalid write of size 4
==277855== at 0x109189: main (in /tmp/main)
==277855== Address 0x4a79054 is 0 bytes after a block of size 20 alloc'd
==277855== at 0x4842788: malloc (vg_replace_malloc.c:446)
==277855== by 0x10915A: main (in /tmp/main)
==277855==
==277855== Invalid read of size 4
==277855== at 0x1091B2: main (in /tmp/main)
==277855== Address 0x4a7908c is 20 bytes before a block of size 256 alloc'd
==277855== at 0x4842788: malloc (vg_replace_malloc.c:446)
==277855== by 0x109168: main (in /tmp/main)
==277855==
19 -> 19
18 -> 18
17 -> 17
16 -> 16
15 -> 15
14 -> 14
13 -> 13
12 -> 12
11 -> 11
10 -> 10
9 -> 9
8 -> 8
7 -> 7
6 -> 6
5 -> 5
4 -> 4
3 -> 3
2 -> 2
1 -> 1
0 -> 0
==277855==
==277855== HEAP SUMMARY:
==277855== in use at exit: 276 bytes in 2 blocks
==277855== total heap usage: 3 allocs, 1 frees, 1,300 bytes allocated
==277855==
==277855== LEAK SUMMARY:
==277855== definitely lost: 276 bytes in 2 blocks
==277855== indirectly lost: 0 bytes in 0 blocks
==277855== possibly lost: 0 bytes in 0 blocks
==277855== still reachable: 0 bytes in 0 blocks
==277855== suppressed: 0 bytes in 0 blocks
==277855== Rerun with --leak-check=full to see details of leaked memory
==277855==
==277855== For lists of detected and suppressed errors, rerun with: -s
==277855== ERROR SUMMARY: 30 errors from 2 contexts (suppressed: 0 from 0)
Le due cose da notare sono le scritture e letture invalide di dimensione quattro (un intero), e il fatto che all'uscita non abbiamo chiamato free su entrambi i blocchi, quindi abbiamo ancora in uso due blocchi.
Fuzzing
Il fuzzing è una tecnica di testing di sicurezza che consiste nell'inviare input casuali, non validi o malformati a un'applicazione per identificare dei bug, crash o comportamenti anomali. Questo approccio automatizzato ha come obiettivo trovare difetti di sicurezza sfruttando particolari input non previsti, che in mancanza di una adeguata gestione da parte del programma, possono indurre in comportamenti inaspettati.
La generazione degli input può avvenire in modo completamente casuale o basarsi su algoritmi predefiniti per coprire casi di test specifici e per migliorare la qualità dell'analisi. Ad esempio, una tecnica comune nei fuzzer è la mutazione, che consiste nel modificare leggermente gli input validi o già utilizzati per creare nuove varianti, con l'obiettivo di deviare dagli input attesi e innescare l'eventuale bug. I fuzzer più avanzati utilizzano la copertura per migliorare l'efficacia dei test: durante l'esecuzione analizzano il programma e registrano quali strade sono state prese dal flusso di esecuzione, e cercano di generare nuovi input in modo da massimizzare la copertura del programma. L'idea è che se un bug si nasconde "dietro" molti controlli, questo tipo di tecnica dovrebbe riuscire a generare un input che superi quei controlli e rediriga il flusso di esecuzione verso il codice che contiene tale bug.
Strumenti come aflplusplus oppure libFuzzer possono essere usati per eseguire fuzzing di applicazioni eseguibili. Molti progetti open-source sono analizzati in modo continuo da Google nel suo progetto OSS-fuzz.